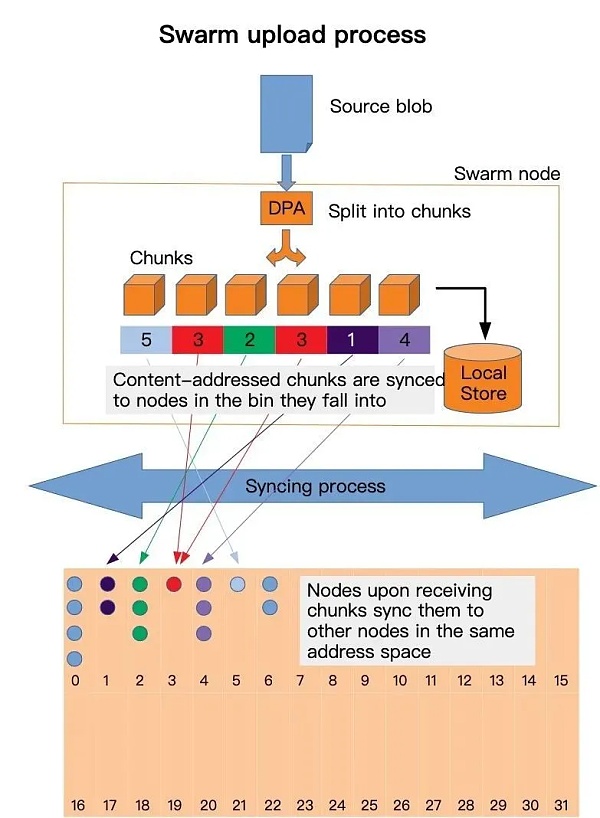
SWARM是个啥 技术总是繁琐的,我尽量简单点。 哈希运算 哈希运算是一系列算法的总称,反正就是对一段数据进行处理,得到一个固定大小(一般是32字节)的结果,这个结果称为哈希值 。并且原始数据不同,得到相同哈希值的概率非常非常非常小,这样的过程称为哈希运算。哈希运算其实是让一个固定长度,相对短的数据来表征一个任意长度的数据。 内容地址 任意的一段数据,对数据内容进行一次哈希运算的结果(哈希值),可以称为这个数据的内容地址。这个称谓的来源是因为地址是由内容决定的。 分布式哈希表 每个节点设备,同样有一个地址,这个地址的来源可以一段随机数的哈希值,一旦生成,节点的地址就不变。这里可以看到节点地址和内容地址是同类型的,这个称为节点与数据“同构”。 既然都是32字节的数据,我们就可以计算两个地址之间的“距离”,这个距离是“逻辑距离”和实际的物理位置无关。计算距离可以有多种算法,最常用的是异或。我们这里为了方便理解,可以理解为两个地址值相减,相减的结果越小,地址就越近。 有了内容地址和逻辑距离的概念,我们可以这样实现分布式哈希表: 任何的数据,在全网中都可以推送到离其内容地址逻辑距离最近的节点上。 这个推送的实现过程可以简化为一句话: 当节点收到数据时,在所连接的邻近节点中,寻找与这个数据的内容地址更近的节点,然后推送给这些节点。 数据的读取过程也可以简化为一句话: 当节点收到数据读取请求时,首先看自身有没有缓存内容地址所对应的数据,如果有,直接取出返回给请求者;如果没有在所连接的邻近节点中,寻找与内址地址更近的节点,把数据读取请求转发给这些节点。 上述的简单方案就可以实现数据的推送和读取。实际的实现中,需要考虑很多异常因素,我们此处不表。 Swarm与IPFS对比 Swarm其实不是存储系统,而是流量分发系统。为什么这么说呢?我们先看一下IPFS系统。 IPFS是存储系统,当文件存储到IPFS节点A上时,IPFS会把文件的信息推送到全网某个地方,后续有其他节点B需要数据时,从该节点获取该文件的文件信息。 这个文件信息中包含文件所在的节点,因此B就知道了文件在A这里,因此B试图与A连接,从A读取文件数据。当节点B读取了文件数据后,同样把自身有的这个文件(或是文件中某个片断)的信息推送到全网某个地方。 后续当节点C需要读取文件时,从全网中找到A和B都有这个文件数据,然后试图连接这两个节点(A和B)读取文件数据,显然随着文件被读取次数的增加,文件在网络中扩散的越多,读取速度也越快,但是在初期速度非常慢,甚至有可能读不到(假设A和B都在内网里),因此IPFS系统里有网络穿透的概念,此处不多描述。 在SWARM中,文件按照4KB大小的片段切割形成一个金字塔结构。然后按照算法将每个片段不断推向某个地方,在推送的过程中,所有的中间节点都会缓存一份数据。 当需要读取该文件时,首先从某个地方读取到这个文件的根,然后从根中读取不同的文件片段信息,然后根据不同的片段从网络中不同的地方读取出相应的内容。 从上述可以明显看到,数据一旦被提交到swarm网络,会被自动切分并且分散推送到全网的不同节点,而在ipfs网络中,这个数据如果没有人读取是不会被扩散的。 swarm的方式可能会提高数据的读取性能,但是数据会被自动推送到不需要存储数据的节点上,浪费宝贵的存储和带宽,这个是IPFS里明确避免的。 反正有得必有失,有失必有得,通过自动扩散,数据内容自动传播到网络中的不同节点以备读取,所以我称其为内容分发系统。 IPFS和Swarm各有其缺陷和优点,那能不能综合两者呢?这个是我们正在做的事情,以后有机会再写文章。 —- 编译者/作者:IPFS看祥子 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
Swarm(BZZ)到底挖了个啥
2021-06-10 IPFS看祥子 来源:区块链网络


LOADING...
相关阅读:
- IPFS代替HTTP已成定局、FIL的未来趋势非常明显2021-06-10
- swarm节点是什么?我们该要怎么去挖bzz币?2021-06-10
- 区块链技术赋能不动产登记2021-06-10
- 观察:为什么以太坊Gas费屡创“新低”?链上数据来告诉你2021-06-10
- Swarm挖矿一机多节点部署最强教程2021-06-10