2022年被称为 AIGC 元年。今年8月,在美国科罗拉多州举办的新兴数字艺术家竞赛中,一副由 AI 生成的名为《太空歌剧院》的作品获得“数字艺术/数字修饰照片”类别一等奖。此次比赛结果引发多方争议,AIGC 由此进入大众视野。?本篇我们将围绕 AI 作画,用 AI 进行100张图的系列创作,从亲身实践出发,并结合背后的模型理论基础和艺术理论基础,与大家共同探讨 AIGC 的现在与未来。? 图片来源:由无界版图AI工具生成 研究团队 | 谢旭璋、侯璐雯、冯寒野、沈浩然 来源:光源资本 我们用 AI 画了100张画秉持“我上我也行”的观念,我们数位艺术小白踏上了 AI 创作之路。创作过程非常简单,用户仅需在 AI 作画软件中输入提示词,便可得到相应的画作,提示词越精准,AI 作画的效果越好。 我们研究了如何使用描述词进行 AI 作画创作,并头脑风暴了10类描述词,一方面尽可能覆盖艺术作品可能关注到的各种题材,如人物与景观、现实与科幻、经典与未来等;另一方面也希望追求一些“节目效果”,希望 AI 能够带来惊喜。 我们选用了目前市面上较为火爆的10款 AI 作画产品,其中海外产品5款,国内产品5款。用这10款产品分别去生成这10类描述词,国外产品输入英文,国内产品输入中文,让我们来看看都生成了怎样的作品。 1)《中国队勇夺2050年世界杯》 是的,即使是 AI 也画不出来中国男足世界杯夺冠的场景。不过要公平的说,我们尝试这一主题的目的是了解 AI 在多人场景上的能力。与肖像画不同,目前的 AI 在表现多人物场景的时候普遍乏力,尤其是肢体、面部的表现上。这并非是中国队的问题,我们也尝试了阿根廷队庆祝进球的场景,同样无法很好的呈现人物形象。  《中国队勇夺2050年世界杯冠军》 描述词:中国男足夺得2050年世界杯冠军,队长在球场中央高举大力神杯,队员们环绕在周围欢呼雀跃,背景是五彩斑斓的礼炮和烟花,影棚光感的,气氛热烈的,极致细节的,高清的,背景虚化,由顶级体育摄影师拍摄 Prompt:The Chinese men's football team wins the 2050 World Cup, the captain holding the Jules Rimet Cup aloft in the centre of the stadium, players surrounding and cheering, colourful salutes and fireworks in the background, studio light, warm and enthusiastic atmosphere, extremely detailed, HD, bokeh, shot by top sports photographers 2)《AI机器人席卷城市》 我们尝试让毕加索来画蒸汽朋克风格的 AI 机器人席卷城市的场景。可以看到,有的作品可能已经放弃治疗了,是十分正经的科幻风机器人风格。另外一些作品看起来有一丝毕加索的味道,例如标志性的几何线条形状拼接等。但想想《格尔尼卡》吧,同样是灾难题材,毕加索用无限的想象力和夸张的表现力将所有情绪充分表达,给人以极强的视觉和心灵冲击,这种感觉在上述十张作品中难觅踪影。  《AI机器人席卷城市》 描述词:AI 机器人席卷城市,燃烧爆炸随处可见,紧张感,压迫感,电影光感,影棚光感,由毕加索创作 Prompt:AI robots sweeping the city, burning explosions everywhere, a sense of tension, oppression, cinematic light, studio light, by Picasso 以下为另外八组主题的 AI 作画作品,我们每组挑选9张图片,供大家赏鉴。         AI 作画带来的冲击和变革 AI 作画带来的冲击和变革作完100张图后,惊讶 AI 的高效之外,我们也切身体会到,AI 将会对内容领域带来一场巨大的冲击和变革。 1)代替重复的辅助环节,提升创作及反馈效率 光学设备和摄影技术出现后,画家画人物面孔时只需要借助光学器材获得定位后,便可迅速推进作画过程,不再需要提前画素描,极大的提升了画家的创作效率。在作为生产资料和工具层面,AI 无疑极大地提升了生产效率,辅助“实现人的想法”。 如我们在创作中发现,像《落日下的海滨城市》、《晨曦中的森林》和《汪星人》等这些 AI 相对容易理解无歧义的语境中,AI 的确产生了非常惊艳的效果,不再需要反复调整便可得到高质量的作品,极大节省了人工画师的时间,对提升初级画师或缺乏经验的初学者的创作效率而言有很大帮助。  2)将创意与实现分离,改变内容生产逻辑 AI 可以直接作为生产资料生产内容,帮助创作者实现创意的落地,但创意的构思和组织才是内容生产的核心。在 AIGC 新型内容生产关系中,人类提供创意的源泉和总体方向,由 AI 从其更庞大且多维度的知识体系当中高效地给出方案和成果,缩短创意-实现-反馈的整体链路,从而给内容创作者更多空间来尝试不同的创意落地,极大提升创作效率的同时进一步丰富内容的多样性,来弥补数字世界愈发多样的内容需求与供给的缺口。 因此 AI 作画并不是挤占艺术行业生存空间的洪水猛兽,相反,它帮助相关从业者完成创意和实现的分离,促进创意更高效落地。如果没有 AIGC,我们团队将永远画不出本文中这100张图,AI 令我们的想象力和创造力从语言真正变成了一幅幅画,甚至在中国画《轻舟已过万重山》中,向来难以用语言描述的意境也体现得很巧妙。  3)生成内容具有随机性,有助于突破创作约束 相对于人类艺术家,AI 可以在短时间内快速大量汲取数据和“学习”前人的作品,学习速度指数级超越人类;另一方面由于 AI 生成内容具有随机性和涌现性,能够帮助创作突破规则和约束,激发创作者更多灵感。 例如 AI 能基于特定条件或完全随机地生成形状、色彩、图案和结构等,产生“未来感”或者“超现实主义感”,有助于帮助人们打开想象空间,赋予了创作更多创新空间。如我们前文所创作的《星际燃烧》,均让我们感慨 AI 的强大“想象力”,为我们的创作提供了更多灵感。  4)迫使人类探索创作力边界,进一步提高创作者能力素质 AI 替人类完成了“探索的过程”,AI 目前的学习样本大多来源于人类的艺术作品并从中总结规律。它可以迫使人类去思考,那些无法被规律总结和学习的东西究竟是什么?即人和 AI 创造力的边界在哪里?虽然 AI 能创作,但产出的作品依然需要人类来筛选和利用,这也要求人类需要具备与时俱进的艺术修养、知识储备以及更深厚的审美功底。AI 带来的不确定性和产出内容的多样性恰恰提高了创作者的审美素养,人类和 AI 在不断的互相学习中共同进步。 正如我们在此次的议题中为了得到更高质量的 AI 作画作品,一次次修改输入词,在重现经典作品《戴珍珠耳环的少女》那幅图中重新解读了原作,再从生成的图中根据结构、光影、人物神态等进行比较和筛选。  AI 作画背后是什么? AI 作画背后是什么?AI 作画的热潮背后,其实是技术与需求同步演变的必然结果。 1)模型突破与算力提升是 AI 作画的技术原动力 2021年之前,AI 生成的内容主要以文字为主,随着新一代模型和算力的提升,文字-图像以及视频等跨模态/多模态内容成为关键的发展节点。 规则模型时代:2012年之前以规则模型为主。 1951年,Alan Turing 提出图灵测试,提出要做出与人类无法区分的智能机器,让机器产生智能这一想法开始进入人们的视野。 此后,科学家不断尝试如何“使人与计算机在一定程度上进行自然语言对话成为可能”。 初期的突破性进展大大提升了人们对人工智能的期望,然而算力及理论的匮乏限制了 AI 的发展。 2000年后随着互联网技术的迅速发展,加速了 AI 的创新研究,促使 AI 逐步走向实用化。 人工智能研究的重心从基于知识系统转向了机器学习方向,但此阶段仍以逻辑规则为主,统计模型效果仍不如预期。 统计模型时代:2012-2017年进入“小模型”+简单输入时代。 2012年ImageNet挑战赛上,Hinton等人提出的深度卷积网络以显著的差异击败第二名的规则方法一举夺冠。 也正是由于该比赛,CNN(Convolutional Neural Network)吸引到了众多研究者的注意,证明了深度学习的巨大潜力。 互联网的逐渐普及也使获取训练数据更加容易。 在这个阶段主要集中在对深度卷积神经网络的探索。 大规模统计模型时代:自2017年以来,大规模统计模型使 AI 逐渐从感知到认知转变。 这阶段开始,AI 研究呈现爆发趋势,2017年由 Google Research 团队发表的《Attention is all you need》提出了全新神经网络架构 Transformer。 Transformer 最初是作为机器翻译的序列到序列模型提出的,但在许多领域都被广泛采用,如自然语言处理(NLP)、计算机视觉(CV)和语音处理等领域。随后的研究工作表明,基于 Transformer 的预训练模型可以在各种任务上实现当时最先进的性能。因此,Transformer 成了 NLP 的首选体系结构。 随着 GPU/TPU 集群等算力的提升和训练语料的进一步丰富,模型参数也逐渐变大,同时由于模型具备更强的并行性,生成高质量的语言模型所需要的训练时间更少。Google 推出的 BERT 和 OpenAI 推出的 GPT-3 随后大放异彩,取得了突破性进展,象征着 AI 逐步在文本、语音、图像识别、语义理解等方面可以达到甚至超越人类水平,AI 开始由感知向认知转变。 2020年后,“大数据+大模型+多模态”逐渐成为新的人工智能研发范式。多模态大模型的出现,让融合性创新成为可能,意味着 AI 既需要具备 NLP、CV 等各自领域相关的大模型理解文本、图像的能力,还要能够跨模态生成全新的内容,为 AI 产生内容带来了更多的想象空间,也让 AIGC 真正走进大众视野。 CLIP 模型 2021年,OpenAI 团队将跨模态深度学习模型 CLIP(Contrastive Language-Image Pre-Training)进行开源。CLIP 模型利用文本信息监督视觉任务自训练,将文字和图像进行关联,如将文字“狗”和狗的图像进行关联。CLIP 模型可以同时进行自然语言理解和计算机视觉分析,实现图像和文本匹配。 在训练数据集层面,为了有足够多标记好的“文本-图像”进行训练,CLIP 模型广泛利用来自互联网上的图文数据,这些图片一般都带有各种文本描述,成为 CLIP 天然的训练样本。CLIP 模型为后续 AIGC 尤其是输入文本生成图像/视频应用的落地奠定了基础。 Diffusion 扩散模型 随后出现的 Diffusion 扩散模型,则真正让文本生成图像的 AIGC 应用为大众所熟知,也是2022年涌现的各类 AI 作画应用的重要模型基础。 Diffusion 模型本质是在前向阶段对图像逐步施加噪声,直至图像被破坏变成完全的高斯噪声,之后在逆向阶段学习将噪声还原为原始图像的过程。经过训练,最终模型可以从随机输入中合成新的数据。但扩散模型的一大缺点就是去噪过程的时间和内存消耗都非常昂贵,这会使进程变慢并消耗大量内存。 2022年,Stable Diffusion 模型通过引入 Latent Diffusion 的方式解决这一问题。通过在较低维度的潜空间上应用扩散过程而不是使用实际的像素空间来减少内存和计算成本,使得模型训练效率极大提高,也让文字生成图片能够在消费级 GPU 上,在数十秒级别时间完成。这一创新大大降低了 AI 创作的门槛,直接推动了 AIGC 技术的突破性进展,也带来了文生图领域的大火。 AIGC 在2022年实现破圈,一方面是由于模型性能有了飞跃式提升;另一方面,AI基础设施的不断进步和发展为多模态大模型提供了庞大的算力支撑,互联网的发展也为模型提供了多类型、大规模的训练数据,进而支撑 AIGC 创作业态的进一步发展。另外,图片作为一种视觉信息的载体,具有天然的优势和传播力,这也进一步造就了文生图领域的火爆。 开源,即开放源代码,任何人可以在源代码的基础上进行学习与修改。优质的开源社区将极大地推动技术的更新迭代、应用落地以及传播。AIGC 技术的传播和普及过程亦从开源中获益诸多。 在算法模型层面,以深度学习模型 CLIP 为例,CLIP 可以通过自然语言监督有效学习视觉概念,有效解决深度学习主流方法存在的若干问题,而开源模式加速了 CLIP 模型的广泛应用,使文本生成图像领域得到了显著进步。 2022年初,Disco Diffusion 的开源引发了开发者对文生图领域的探索和创作,而2022年下半年 Stable Diffusion 的火爆不仅由于模型层面的创新,也是由于形成了良好的开源社区氛围,以开源的方式缩短了行业技术进步所需要的时间。Stable Diffusion 模型开源后短短几个月时间出现大量的二次开发,从模型本身优化到应用拓展以及插件,大量开发者和用户进行传播和创作,也直接引发了2022年 AIGC 的火爆。 在训练数据集方面,开源也为 AIGC 模型的训练提供了充足的原材料。LAION 作为全球非盈利机器学习研究机构,在2022年开放了当前规模最大的开源跨模态数据库 LAION-5B,包含超过50亿图像文本对的数据集,进一步扩展了语言视觉模型的开放数据集规模,使得更多研究者能够参与到多模态领域中。另外还提供多个子集用于训练各种规模的模型,从而进一步推动研究成果,加快 AI 图像生成模型的成熟。 此外在提示词(Prompt)方面,作为 AI 作画领域重要的输入,用户和研究人员在开源社区持续分享提示词技术方面的突破,用于探索目前模型的潜在能力,也进一步降低了 AIGC 的使用门槛,让更多普通用户可以生成满意的图片。 2)AIGC 是内容行业发展的内在需求 内容消费量增加,急需降低生产门槛,提升生产效率 内容消费的碎片化对内容的总体需求量与产出的多样性有了更高要求,而这一需求进入元宇宙会更加明显。需要海量内容来填补数字世界内容的供给缺口,软件工程师、画手等拥有创作能力的专业人士将成为稀缺人力资源。AIGC 可以通过提升原有人群的创作效率,以及赋能非专业人士完成。 内容消费升维,消费者要求更为丰富的感官体验 随着相关内容消费硬件的提升,消费者对内容形态要求也会更高。从2G时代的文字,3G时代的图片,4G时代的视频,以及5G时代将充分增长的直播,通信及硬件的持续迭代使得主流的内容消费形态不断变化,消费内容不断升维。无论是更高质量的视频或 CG 内容,还是预估将成为下一代主流的 VR/AR 内容,提供更加海量和丰富的感官体验已经成为一种必然。 内容生成个性化和开放化,User 端表达意愿有明显上升 内容消费逐渐从内容本身转移到内容的参与者身上,参与者希望能够对内容本身施加更多的影响,例如具有一定不可预测性,或是和个人绑定的特殊情节/特征。在这种思路下,二次内容创作的占比将有所提升,内容在抵达每个个体时都需要通过工具进行二次改造和发散。 AI 作画会取代画师吗?“AI 是否会取代人类画师?”这个问题伴随着 AIGC 的浪潮也在不断地被讨论。为了回答这个问题,我们不仅用 AI 创作出以上100张图,也仔细研读了近20篇关于 Diffusion Model 以及在此模型基础上衍生的论文。与此同时,由于绘画作品在艺术及人文价值上的特殊性,我们认为,围绕AI作画的讨论有必要从艺术发展的规律切入,探讨新一代 AI 作画技术将驶向何方。 1)技术从未“杀死”绘画,反而紧密交织促其进步 我们阅读了大卫·霍克尼和马丁·盖福德的《图画史》以及其他艺术史总结,试图从中寻找一些图片或艺术发展的规律。事实上,人们讨论艺术史的时候,经常会将绘画史、摄影史、电影史分开论述,却鲜有将“图画”视成一个整体来讨论。但从公元前1-2万年的洞穴石壁到如今的电子屏幕,图画无处不在。图画可以是一切再现三维世界的平面,不管是洞穴壁画、绘画、照片,还是如今 AI 作图所产生的作品,我们在此均将其定义为“图画”。 如今对 AI 作画的讨论,无疑会让人们联系到19世纪摄影技术的问世对画家的冲击。事实上,摄影可以说是“绘画的孩子”,早在19世纪早期摄影术发明之前,“暗箱”已经是18世纪常见的绘画器材,画家借助光学投射的图画观察世界。 当时对这种行为也出现了很多对峙的声音,18世纪诸多画家曾严厉告诫同行不得使用暗箱作画,可同时他们自己却在偷偷使用,这种公开发声和实际行为不一致的现象一直持续到19世纪摄影术发明后。如比利时象征主义画家费尔南·赫诺普夫 (Fernand Khnopff)公开表明“摄影术是根植于平庸的奴隶般的媒介”,但在他去世后却在他的工作室找到了为他油画提供灵感和姿势的照片。 这批在公开场合反对的画家夹杂着对新技术的惊喜和疑虑,这一复杂和矛盾的心理也是几个世纪以来艺术家们对新技术冲击的典型心态。 意大利风景画家卡纳莱托(Canaletto)便把他从相机得来的初始视觉数据投入巨大的脑力运算和想象调整中,将相机观察和早年从舞台设计训练中获得的经验结合起来,因此他的艺术混合了两者——高度自然主义的相机所见,混合着巴洛克时代意大利剧场布景的错觉主义技巧。18世纪的画家已然在面临相机带来的冲击,但是最好的一批画家依然找到了即使用这种工具又不至沦为其奴隶的办法。  《圣马可广场》卡纳莱托 而19世纪末、20世纪初出现的“画意摄影主义(Pictorialism)”进一步说明了两者的融合:一些最好的照片是由画家——比如德加和埃金斯拍出的,同时许多摄影家却在奋力模仿油画的效果。此外,摄影的出现对写实绘画产生了一定冲击,同时却也促使画家不再局限于客观复现一个景象,反而更注重自我主观意愿的表达,倒逼艺术寻找其他出路,也促进了其他流派的发展。 另一方面,正是摄影技术的出现才进一步促进了艺术有着更加多样的发展方向。在摄影技术发明之前,人们用线刻版画等技术复制画作,但有了摄影人们才真正有可能对藏于不同地方的大量画作进行比较和编纂。 2)AI 与人类作画的共性:基于输入的还原与重组 “好的艺术家懂复制,而伟大的艺术家则擅偷取。”如果我们将 AI 称为“好的艺术家”,能快速学习并复制前人优秀作品,那么人类依然可以被称为“伟大的艺术家”,因为人类不仅有学习和复制的能力,更有 AI 所不具备的感知力,人类学习的不仅是前人优秀的二维、平面的艺术作品,更是用感官对这个现实三维立体世界的全面感知。 AI 作画所基于的扩散模型(Diffusion Model) 在本篇不作太多严谨的技术性探讨,为了方便理解,在此我们将其简单地理解为两个过程,“前向扩散过程” (从X 0 到X T 的过程) 即通过逐步对一张真实图片添加高斯噪声直到最终变成纯高斯噪声图片。而反向扩散过程 q(x t-1 |x t , x 0 ) (从X T 到X 0 的过程) 则是前向扩散过程 q(x t |x t-1 ) 的后验概率分布,和前向过程相反是从纯高斯噪声图逐步采样得到真实图像X 0 。 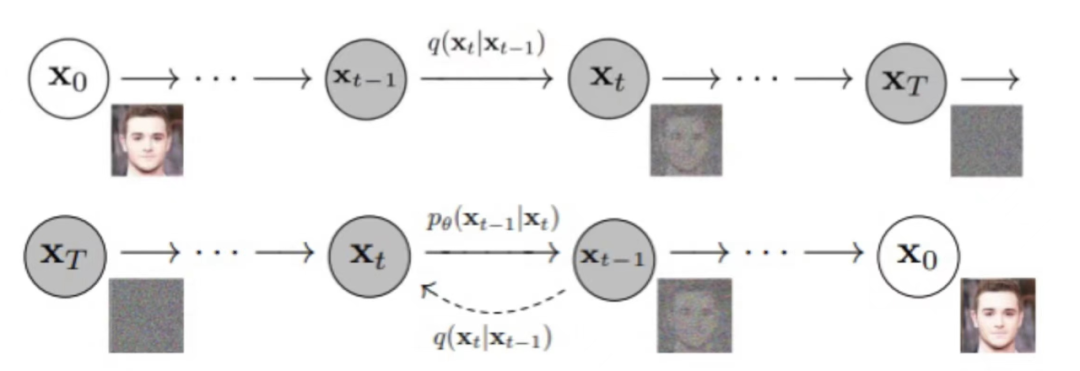 由 AI 的创作过程可知,AI 的“输出”需要预先“输入”大量的图文数据,因此我们也能够笃定地做出这样的结论,它并不能创造出它所不了解的、不认识的、从未接触过的、不存在的东西。它的任何创作都需要经过大量数据的训练,即对人类作品的大量收录和学习,AI 的输出是基于输入的还原和重组,AI 并不会抽象的“凭空创作”这一种能力;并且在“输入”的过程中,AI与现实世界隔了一层,即人类是直接对现实中三维世界进行观察和总结,从而创作文艺作品,而 AI 则还要隔着一个人类的文艺作品来观察和总结。 人在学习和创作的过程中,也是先用感官去面对事物,包括已存在的二维平面作品以及三维的立体世界作为训练数据“输入”,这些信息经过“人类的 CPU”大脑处理,紧接着这些被大脑处理过的信息和选定的载体结合,作为“输出”传达出去。 而在这个过程中,大脑对信息的加工和处理不仅包含人类对“输入”的直接理解,还包含着因过往经验和规律的总结和思考。不管是对“输入”的处理还是对过往规律的总结,都和 AI 的训练过程有异曲同工之处:人类大脑读过的每本书、经历的每件事都在影响着大脑对信息的判断和处理,就像喂给 AI 更多的训练语料和数据,AI 就能不断“成长”,变得比原来更加智能。 但大脑的“算法”除了对规律性的总结之外,还有更多偶然性和随机性的“创造力”,以及因人类具有腺体和激素所产生的情绪和感知力, 这部分令大脑的“算法”更像是一个黑匣子而不是数学公式,也并不是一个规律性加噪和去噪的过程。大脑经过一系列处理后,将产生的信息作为“输出”传达出去,令“输出”不仅仅是“输入”的简单复刻和处理。因此不同的人类大脑在面对同一信息,会以完全不同的方式进行处理。 3)艺术层面:AI 无法复制艺术的张力和精髓 如今 AI 可以对大量前人画家的画作进行解码和学习,当我们给 AI 足够多的学习数据,它可以从中总结很多规律,但这些规律都是一些主流规律,AI 也只能重现部分主流风格和模式。但它所能做到的也只是重现这些东西,模仿到的只是皮毛的风格。 对于图画的观看者来说,感受层面的冲击还无法总结成规律,我们也可将其称为这幅画的“张力”,这些画的力量也许在于它的笔触、结构以及它传达的情感。AI 对前人画家作品进行足够多的输入和“学习”,通过数学公式来输出它所“理解”的结果,输出的过程需要生成不同结果反复进行枚举,再由人去挑选。在这个过程中,依然有很多作品想要传达的情感无法被 AI 总结成规律。而不同的艺术家甚至同一个艺术家在不同的时期想表达的理念、体验和设计手法却各有差别。 比如上文中,我们 AI 用毕加索风格来生成《AI 机器人席卷城市》这一主题,可以看到 AI 对空间和时间的捕捉仍然停留在很基础的水平,相邻物体间的接缝略显笨拙和生硬。当我们用 AI 去复刻经典名画《戴珍珠耳环的少女》时,虽然 AI 学到了整体的构图甚至是光影,但人物眼神中传达的故事和情感却有所缺失。  4)技术层面:AI 作画对整体构图与细节的处理远不及人类 人喜欢图画,因为它是鲜活的。图画背后本质是创作者对这个世界的观看、理解和感知,AI 将学习到的二维平面复制转化为另一个二维平面,对多人物同时出现同一空间的结构、距离和透视关系等经常处理的不尽人意,这是由于 AI 是以局部来拼凑整幅画作,并未完全理解画中的人物和空间关系。 比如在《中国队勇夺2050年世界杯冠军》一图中,AI 对球员之间的距离和位置关系处理的效果并不好,对大空间下多人画面的细节处理甚至还会出现“恐怖谷”效应。  而人类则是将观察到的三维世界转化为二维平面。 绘画的本质是一门时间和空间的艺术,素描将被描绘物体放进空间,而对叙事画家来说,则尽可能地在一幅固定、静止的图像中重述他所想讲述的故事,让它在时间中逐渐展开。人类通过创作来进行对时间和空间的思考,以及完成“自我”表达。 因为创作对于作者而言,是无法预知,没有定律的,其价值不只在于成品,更在于“自我探索”的过程。AI 无法替人类完成自我对内探索和对外观察的过程,人类的创作欲将会永远需要一个出口。对于作者而言,“自我”是不可被 AI 替代的。 此外,虽然 AI 画图在输入词不断调试后,可以生成较为满意的图片,但是如果对图片的各种细节进行微调,AI 所生成的结果依然像“潘多拉的盲盒”,由程序自动生成的图像很难保留想要的部分而微调需要修改的部分,因为 AI 并不能真正理解这些修改的意义。 以我们作画的经验来看,AI 对手的理解和人类不同,它并未从生物和空间结构去理解。在我们生成《窗边少女》过程中,经常会出现 AI 完美地生成了脸,但却有2根或者4根手指的情况。并且大多数情况下生成的手的形状并不符合手的骨骼和肌肉走向,尤其是在十指相握时,给人一种畸形的感觉。 在人的常识和认知中,手是一种有多个面的部位,每只手最多有5根手指,并且它们在一定限度内顺序摆放,弯曲,变动位置,存在阴影。比如一个比“耶”的剪刀手手势,人类可以用常识和社会性含义来理解,但在 AI 眼里,它可能就认为这就是一种仅长出两根指头的手,而且难以理解剪刀手的空间结构。  类似手的处理这样的细节“低级错误”在AI作画的过程中还有不少,因为AI在有限算力的条件下会选择精细地画好某些显眼部位而忽视一些细节。对于各种手势的分类以及理解,AI 选择牺牲一定精准度来保持效率。对效率的提升来说无可厚非,只是这也说明了局部细节的处理和微调上,AI 尚未达到真正的“智能”。 最后,我们尝试让最近大火的 ChatGPT 和 AI 作画软件进行了一番梦幻联动,让 ChatGPT 为光源资本写一句 Slogan,再用这句 Slogan 作为提示词用 AI 作画软件来作画。 ChatGPT 给了我们这样的回答: “Empowering entrepreneurs to shine their light on the world.”  而 AI 作画软件给了我们这样的作品:  一束光芒照向前路,或许 AIGC 也正为我们照出更光亮的未来。 说明 [1] 本文所使用的 AI 作画产品仅供研究使用,因此不在文中进行列举,也不视作任何投资建议; [2]?本文所使用的图均为 AI 作画产品生成,仅供本文研究使用。 参考文献 [1] 2017.12,?Google?Research,?Attention?Is?All You Need,https://arxiv.org/pdf/1706.03762.pdf [2]?2019.11,澎湃新闻,《深度:谁是AI开源世界之王?》,https://www.thepaper.cn/newsDetail_forward_4931100; [3]?2021,?OpenAI,?Learning transferable visual models from natural language supervision中文版,https://zhuanlan.zhihu.com/p/432590298; [4]2022.09,AI 科技评论, 最近大火的DiffusionModel,首篇扩散生成模型综述,https://mp.weixin.qq.com/s/RPKEsnZmq-V5kxYt67U6PA; [5] 2022.11,知乎,《Stable Diffusion原理解读》,https://zhuanlan.zhihu.com/p/58456272; [6]?2022.11,?Deephub,《Stable Diffusion的入门介绍和使用教程》,https://zhuanlan.zhihu.com/p/584562722 ; [7]?2022.11,李rumor,读了14篇论文,终于会拿捏Diffusion了,https://mp.weixin.qq.com/s/brvSAAmhkSKTTOXZqT0HKQ; [8]2022.11,腾讯科技,《一文读懂AIGC:万亿新赛道为何今年获得爆发?》,https://mp.weixin.qq.com/s/Sid6BbRqmJbcaCCmLFJJoA; [9] 2021,浙江人民美术出版社,《图画史:从洞穴石壁到电脑屏幕》 [10] 2022,电脑知识与技术,《Transformer 研究概述》,https://www.zhihu.com/market/paid_magazine/1512515556967710720/section/1512515783565090817?origin_label=search; —- 编译者/作者:AI之势 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
从图画史看 AIGC,我们用 AI 作了100幅画
2022-12-11 AI之势 来源:区块链网络
LOADING...
相关阅读:
- 花 650 万美元买 30 秒广告,这家 Paradigm 投资的 Web3 游戏公司是大冤种吗2022-10-19
- 1句话生成视频AI爆火!Meta最新SOTA模型让网友大受震撼2022-09-30
- 巴比特 | 元宇宙每日必读:DigiDaigaku、Doodles、Azuki等蓝筹NFT接连获得大额2022-09-30
- 上线一个月成为准独角兽、上万人排队注册,AI Art是下一个NFT?2022-09-30
- Blockchain.com获迪拜虚拟资产监管局临时批准开设办事处2022-09-10