欢迎来到ProtoSchool!在深入探讨代码挑战之前,让我们花一点时间看一下去中心化网络背后的一些概念。与我们的其他教程不同,该教程是无代码的,旨在向您介绍在ProtoSchool中会遇到的一些关键术语。让我们开始吧! 什么是数据结构? 无论您是不是程序员,每天都被数据结构所包围。列表,词典和目录都可以帮助我们组织信息并考虑各种数据之间的关系。 来自维基百科: 在计算机科学中,数据结构是一种数据组织,管理和存储格式,可实现高效的访问和修改。更准确地说,数据结构是数据值,它们之间的关系以及可以应用于数据的功能或操作的集合。 在编程中,数据结构无处不在。将数据组织为变量以便在程序中使用它们的方式涉及数十到数百万个数据结构。如果您是开发人员,则可能熟悉数组,对象,图形等常见数据结构。 分散的数据结构 在分散的网络上,我们直接从同级而不是从中央机构访问数据,我们需要专用的数据结构来允许我们验证和链接各个内容。通过分散系统共享的数据结构必须是可验证的。在单个系统(例如您自己的笔记本电脑)上,您对在内存或磁盘中使用的数据结构有更高的信任度。但是在去中心化系统中,对等方之间的信任较少或可能为零。 大型数据结构还必须能够在许多同级之间分布并链接在一起,以实现分散化。就像任何网页都可以链接到其他位置的另一个网页一样,分散的数据结构实现了互连数据的网络。 二、集中式Web:基于位置的寻址在深入研究共享在去中心化网络上的工作方式之前,让我们花一点时间检查一下我们如何习惯于访问数据。 使用网址定位 URL(统一资源定位符)是我们彼此提供的主要地址,用于集中式Web上的数据(您知道,我们都曾经使用过那种普通的老式Web)。它们使我们能够创建链接和连接Web上的数据,因此它们具有重要的意义。(如果没有链接,Web将会非常糟糕!)但是,URL是基于存储数据的位置,而不是基于存储在那里的资源的内容。我们称此为地址寻址,这给我们带来了一些问题。我们大多数人在URL方面都有丰富的经验,我们根据经验对URL进行一些假设。 https://www.puppies.com/beagle.jpg例如,当我们看到时 ,我们可能会根据文件名和扩展名猜测存储在该位置的数据是小猎犬的图像(JPEG格式),但是我们不能仅通过URL对此进行验证。很可能有一张奇瓦瓦beagle.jpg狗的照片藏在一只可爱的小猫身上,甚至更糟糕的是! 通过域名,URL指示我们应访问该数据的权限。即使在某种程度上已经分散了网络(因为任何人都可以链接到其他人),但是引用数据的链接是基于位置的,因此,数据本身必须集中在授权机构上,以便我们找到它。就像对文件名一样,我们对这些权限(或域)进行假设。例如,我们可能假设托管于的文件比托管于的文件puppies.com更安全地打开evilhacker.com,但是我们不确定。 最终,托管在集中式Web上的文件的内容与其基于位置的地址没有直接关系。如果我们看到一只可爱的小狗的照片并被告知存储在网络上,则我们无法猜测会导致我们进入该图像的URL。我们既不能确定告诉谁托管它的域,也不能确定文件名。 集中式网络上的信任和效率 由于我们无法验证哪些内容驻留在特定的URL上并且依赖于中央当局(以及人类善良)来对事物进行真实标签,因此我们很容易受到恶意行为者的欺骗。对于42,000人来说,存储与那只可爱的小猎犬完全相同的照片也很容易,但是它们都存储在不同的域中,并使用不同的文件名,从而导致大量冗余。让我们面对现实吧,即使是在我们自己的笔记本电脑上,我们大多数人不小心也保存了相同的文档,download.pdf而download(01).pdf没有意识到它,或者一遍又一遍地将同一学期论文的迭代保存v1或2018-12-18添加到标题中。网络是一堆混乱的数据,这些数据已在不同的URL上多次保存,并且没有简便的方法来区分哪些项目彼此相同。 肯定有更好的办法! 三、去中心化的网站:内容寻址如我们所见,集中式网络依靠值得信赖的权威机构来托管我们的数据,并使用基于位置的URL来访问它。但是还有另一种选择。在去中心?化的网络上,我们所有人都可以托管彼此的数据,并通过另一种更安全的链接来托管彼此的数据。 密码学哈希 加密散列是分散数据结构工具箱中最重要的工具。它打开了一种新的链接方式,即内容寻址,从而使我们摆脱了对中央当局的依赖。散列可接收任何大小和类型的数据,并向您返回一个代表该数据的固定大小的“散列”。散列是一串看起来像gobbledygook的字符,但是您可以将其视为数据的唯一名称。它可能看起来像这样: zdpuAsHkamdCQgrDrNSwJVgjMkQWoLxdrccxV6qe9htipNein 坦白地说,这些名称目前对人类并不友好(beagle.jpg描述性更强!),但它们的安全性更高。原因如下: 加密散列可以从数据本身的内容派生而来,这意味着对同一数据使用相同算法的任何人都将到达同一散列。如果Ada和Grace都使用相同的分散式Web协议(例如IPFS)来共享完全相同的小猫照片,则两个图像将具有完全相同的哈希值。通过比较这些散列并确认它们是相同的,我们可以保证这两张照片的每个像素都是相同的。加密哈希是唯一的。如果Grace使用Photoshop从那只猫咪中去除了一根胡须,则更新后的图像将具有新的哈希。只需查看该哈希,即使没有访问文件本身,也很容易看出该文件现在包含不同的数据。 分散网络上的信任 在集中式Web上,我们学会了信任某些权威而不是其他权威。我们会尽力利用URL的线索,但是有些恶意行为者利用位置寻址的缺点来欺骗我们。但是,在分散的网络上,我们都参与并托管彼此的数据,而内容寻址使我们能够信任共享的信息。我们可能对托管数据的对等节点知之甚少,但哈希可以阻止恶意行为者欺骗我们有关文件内容的信息。这就是使得加密散列对分散式网络如此重要的原因。 向同伴索要内容 使用传统的位置寻址,我们知道我们需要访问域puppies.com以查找存储为的内容beagle.jpg。如果puppies.com域名由于某种原因被破坏,我们将无法访问该图像。 分散式网络的工作方式有所不同。当我们想要一张可爱的宠物的特定照片时,我们会通过其内容地址(哈希)来要求它。我们问谁?全网!如果Ada在线,我们将看到她具有我们要查找的内容,并且我们知道它正是我们需要的文件,因为它具有匹配的哈希值。如果她下线,我们仍然可以从Grace或其他同伴那里获得相同的照片。由于我们使用散列在分散的Web上请求数据,因此我们可以将散列视为链接,而不仅仅是名称。 四、加密哈希和内容标识符(CID)到目前为止,我们只讨论了可爱的图片,只是为了大家开心,但是内容寻址可以用于所有不同类型的文件和数据,从JSON对象到术语文件再到视频。为了使加密哈希工作,我们需要知道正在使用的数据格式并使用适当的工具。 解码数据结构 A?CID (Content Identifier)是分散网络上使用的一种特定形式的内容寻址。它是为IPFS(一种去中心化的Web协议而开发的 ,我们将在以后的教程中对其进行讨论),但是它具有广泛的含义。 A CID是包含加密哈希和编解码器的单个标识符,其中包含有关如何解释该数据的信息。编解码器以某些格式对数据进行编码和解码。
许多格式和协议已经使用内容寻址。其中包括Git之类的工具以及以太坊和比特币之类的协议,但是它们在解释数据的方式以及用于散列的加密功能方面有所不同。 CID允许我们为这些系统中的任何一个创建通用标识符。每个CID是一个标识符,其中包含codec用来解释数据的标识符,一个multihash是自描述的哈希值(一个告诉您创建该哈希值的哈希函数类型的哈希值)。
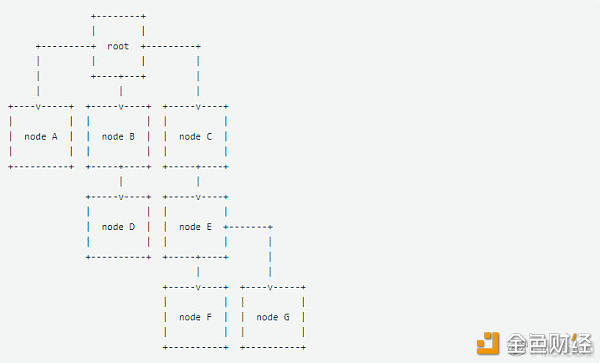
不同数据结构之间的链接 CIDs使我们能够构建以完全不同的格式链接到其他数据结构的数据结构。想象一棵JSON对象树,这些树链接到BSON对象,而BSON对象也链接到git commits。(或者想象一个包含小狗图像和小猫视频的目录,以及一个包含有关长颈鹿文章的子目录。可能性无穷无尽!)从这棵树一直到现在,我们都有加密散列,可以让我们分发和链接数据。 为什么在不同的数据结构之间进行链接很重要?每天在集中式网络上,我们从文本到图像,从徽标到主页,从电子邮件到PDF链接。链接将资源联系在一起,传达含义,并使网络互动性极强! 五、默克尔树和有向无环图(DAG)正如我们已经讨论的那样,分散的Web依赖于链接的数据结构。让我们探索一下它们的外观。默克尔树甲梅克尔树(或简单的“哈希树”)是一种数据结构,其中每一个节点被散列。
在Merkle树中,节点通过其内容地址(哈希)指向其他节点。(请记住,当我们通过密码哈希来运行数据时,我们会获得一个我们可以认为是链接的“哈希”或“内容地址”,因此Merkle树是链接节点的集合。)如前所述,所有内容地址对于它们表示的数据都是唯一的。在上图中,node E包含对node F和的哈希的引用node G。这意味着的内容地址(哈希)对于node E包含这些地址的节点是唯一的。 迷路?让我们将其想象为一组目录或文件夹。如果在包含子目录F和G的情况下通过哈希算法运行目录E,则返回的内容派生哈希将包含对这两个目录的引用。如果我们删除目录G,就像Grace从她的小猫照片中删除该晶须一样。目录E不再具有相同的内容,因此将获得一个新的哈希。构建上面的树后,根节点的最终内容地址(哈希)对于一棵树是唯一的,该树包含该树下所有节点。如果任何节点中的数据甚至要改变一个字节,那么更改后的节点的哈希值就会改变,其所有父节点的哈希值也会改变。如果您没有注意到,这意味着作为程序员,您将始终需要从叶节点到根节点向后构建这些数据结构。有向无环图(DAG)
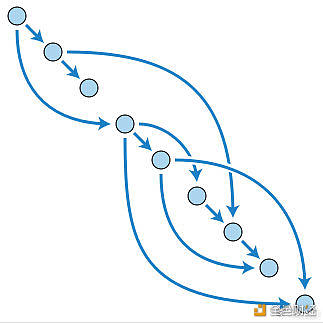
DAG的首字母缩写是Directed Acyclic Graph。这是描述特定种类的Merkle树(哈希树)的一种好方法,其中树中的不同分支可以在单个向前方向上指向树中的其他分支,如上图所示。 本文转载于协议实验室学校网站。 —- 编译者/作者:FilCloud 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
转载于协议实验室学校,IPFS-分散的数据结构
2019-11-26 FilCloud 来源:区块链网络



LOADING...
相关阅读:
- 猕猴桃溯源?利用IOST区块链技术进行农产品溯源2020-08-01
- MYKEY第一时间推出YAS工具助力币东兑换EIDOS(附兑换教程)2020-08-01
- 锁定DeFi的总价值创下了$ 4B的新ATH2020-08-01
- 传统交易所平台币也登录Uniswap?看看各交易所花式蹭热度的动作就能感2020-08-01
- 收益农场从金融向数字收藏品拓展2020-08-01