标注或者去匿名化区块链的思路可以让区块链分析更好地生态中已知参与者的行为模式和特征。直觉上我们可以考虑创建一些规则来分析区块链生态系统中的不同成员,例如: “如果一个地址持有大量比特币地址并且一次执行100个交易,那么这是一个交易所地址……” 虽然很有吸引力,但是基于规则的方法将很快失效,无法再提供有用的信息。下面列出了部分原因: 1. 预置知识的完整性:基于规则的分类会假定我们对于如何识别区块链生态中的 不同参与者有足够的知识。这显然是不正确的假设。 2. 持续的变化:区块链解决方案的架构一直都在演变,这对任何嵌入的规则而言都是挑战。 3. 特征属性的数量:创建一条有两三个参数的规则很简单,但是试图创建一条有几十个甚至上百个参数的规则就没那么简单了。要识别出像交易所或OTC柜台这样的 地址需要大量的特征。 因此我们不能使用预置的规则,我们需要一种可以从区块链数据集中学习模式的机制来自动推断出有意义的规则让我们可以标注相关的参与方。从概念上来说,这是一个经典的机器学习问题。
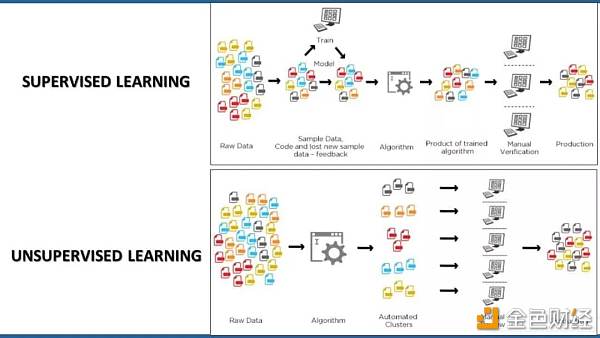
从机器学习的观点,我们应该从两个主要途径来考虑应对去匿名化的挑战: · 无监督学习:无监督学习聚焦于学习指定数据集中存在的模式并识别相关分组。在区块链数据集的上下文中,可以使用无监督学习模型基于地址的特征将其匹配到不同的分组中并对这些分组进行标注。 · 监督学习:监督学习方法可以利用已有的知识来学习指定数据集中的新的特性。在区块链上下文中,可以使用监督学习方法基于已有的交易所地址数据集训练一个模型来识别出新的交易所地址。
去匿名化或者给区块链数据集打标签很少是只用监督学习或者只用非监督学习,更多的情况下需要两种方法的结合。机器学习模型可以有效地学习区块链生态系统中特定参与者的特征,并利用这些特征来理解其行为。 在使用区块链ETL工具将区块链原始数据加载到数据库或大数据分析平台后,将标注层引入区块链数据集是进行更有价值的区块链数据分析的一个关键挑战。 这些标签提供了更好的上下文环境,也让区块链分析模型具有更好的可解读性。不过尽管我们有机器学习这样强大的工具,去匿名性依然是分析理解区块链生态系统的道路上一个不可忽视的重大路障。 —- 编译者/作者:和数钱包 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
LikeLib:机器学习如何分析解决“去匿名化”这个大难题
2019-12-05 和数钱包 来源:区块链网络

LOADING...
相关阅读:
- 专家说,区块链是澳大利亚网络安全解决方案的一部分2020-07-31
- MDUKEY的区块链数据隐私治理逻辑实践:Code is law2020-07-28
- 区块链数据索引项目 The Graph 推出激励性测试网 Mission Control2020-07-28
- BSN“分裂”可以刺激中国的区块链领域走向全球2020-07-26
- 评测:BHP——专注算力的服务平台2020-07-23