统计悖论在机器学习模型中无处不在。以下是一些最闻名遐迩的例子。
用人工智能(AI)重建人类认知需要处理许多无法用数据来解释的现象。悖论长期以来一直被视为违反逻辑和数据规则的离群情况。通过悖论进行推理对机器学习模型来说是一个难以想像的挑战,因此,数据科学家在训练新模型时应该意识到这些场景。 悖论是人类认知的奇迹之一,很难用数学和统计学来解释。从概念上讲,悖论是一种基于问题的原始前提得出明显自相矛盾的结论的陈述。即使是最著名的和记录最详细的悖论也经常愚弄该领域下专家,因为它们从根本上违背了常识。当人工智能(AI)试图重建人类认知时,机器学习模型在训练数据中遇到矛盾的模式并得出乍一看似乎矛盾的结论是很常见的。今天,我想探讨一些著名的悖论,它们通常出现在机器学习模型中。 悖论通常是在数学和哲学的交叉点上形成的。一个闻名遐迩的哲学悖论被称为忒修斯之船,它提出了这样一个问题:一个被替换了所有部件的物体是否仍然是同一个物体。首先,假设英雄忒修斯在一场大战中驾驶的那艘著名的船被作为博物馆收藏在港口。随着时间的流逝,一些木制部件开始腐烂,被新的部件所取代。大约一个世纪后,所有的部件都被替换了。“修复”后的船还是原来的船吗?或者,假设每一块被移走的碎片都被储存在一个仓库里,一个世纪之后,技术的发展修复了它们的腐烂,并使它们能够重新组装在一起,制造出一艘船。这艘“重建”的船是原来的船吗?如果是的话,港内修复的船还是原来的船吗?
数学和统计学领域充满了著名的悖论。举几个著名的例子,传奇的数学家和哲学家伯特兰·罗素Bertrand Russell提出了一个悖论,揭示了了史以来最伟大的数学家之一:格雷格·康托Greg Cantor的集合论中最强大的思想中的一个矛盾。本质上,罗素悖论质疑“不含自身的列表的列表”是否正确。通过考虑所有非自身成员的集合的集合,在本集理论中产生了悖论。当且仅当它不是自身的成员时,这样的集合似乎是自身的成员。因此出现了悖论。有些集合,例如所有茶杯的集合,不是它们本身的成员。而其他集合,例如所有非茶杯的集合,是它们自己的成员。我们可以称所有不属于它们自己集合的集合为“R”,如果R是它自身的一员,那么根据定义,它一定不是它自身的一员。类似地,如果R不是它自身的一员,那么根据定义,它必须是它自身的一员。什么鬼? ? ? ?
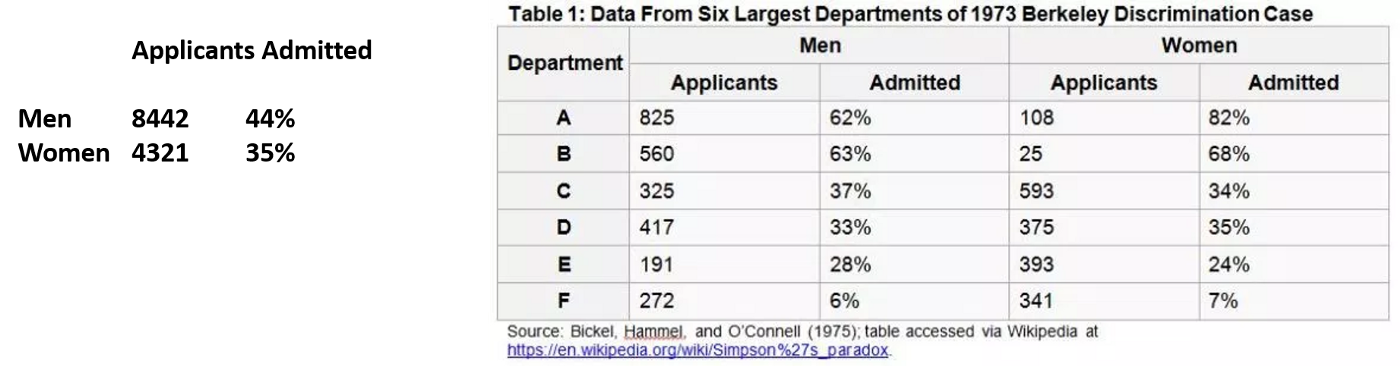
机器学习模型中著名的悖论 作为任何基于数据的知识构建形式,机器学习模型也不能避免认知悖论。恰恰相反的是,当机器学习试图推断隐藏在训练数据集中的模式,并在特定环境下验证他们的知识时,他们总是容易得到自相矛盾的结论。以下是机器学习解决方案中出现的一些最闻名遐迩的悖论。 辛普森悖论 辛普森悖论是以英国数学家爱德华·辛普森Edward Simpson的名字命名的,它描述了一种现象,几个组的数据中很明显的趋势会随着这些组中的数据的合并而消散。1973年发生了一个现实生活中的悖论案例。对伯克利大学研究生院的录取率进行了调查,导致这所大学因性别差异而被女生起诉。当时的调查的结果是:对每一所学院(法律、医学、工程等)分开考察时,女生的录取率高于男生!然而,平均来看,男性的录取率比女生高得多。这怎么可能?
对前面的现象的解释是,简单的平均值不能说明整个数据集中特定组的相关性。在这个具体的例子中,大量女生申请了录取率较低的学院:比如法律和医学。这些学院录取率不到10%。因此,被接受的女生比例很低。另一方面,男生倾向于申请高录取率的学院:比如工程类,其录取率约为50%。因此,男生被接受的比例非常高。 在机器学习的背景下,许多无监督学习算法推断出不同的训练数据集模式,这些数据集组合在一起会产生矛盾。 布雷斯悖论 这个悖论是在1968年由德国数学家迪特里希·布雷斯Dietrich Braes提出的。以拥挤的交通网络为例,布雷斯解释说,与直觉相反,在道路网络中增加一条道路可能会降低交通流量 (例如,每个司机的行驶时间);同样,关闭道路可能会潜在地改善出行时间。布雷斯推理基于这样一个事实:在纳什均衡博弈中,驾驶员没有改变路线的动机。从博弈论的角度来看,如果其他人坚持使用相同的策略,那么个人在应用新策略时就不会有任何收益。对于司机来说,策略就是采取的路线。在“布雷斯悖论”的情况下,尽管整体表现有所下降,但司机们仍会继续切换,直到达到纳什均衡。因此,与直觉相反,关闭道路可能会缓解交通拥堵。
布雷斯悖论与自主多智能体强化学习非常相关,在这种情况下,模型需要根据未知环境中的特定决策来奖励智能体。 莫拉维克悖论 汉斯·莫拉维克Hans Moravec可以被认为是近几十年来最伟大的人工智能思想家之一。上世纪80年代,莫拉维克对人工智能模型获取知识的方式提出了一个反直觉的命题。莫拉维克悖论指出,与人们普遍认为的相反,高层次的推理比低层次的无意识认知需要更少的计算。这是一个经验性的观察结果,它与“计算能力越强,系统就越智能”的观点背道而驰。 构建莫拉维克悖论的一个更简单的方法是,人工智能模型可以完成极其复杂的统计和数据推断任务,而这些任务对于人类来说是不可能完成的。然而,许多对人类来说无足轻重的任务,如抓取物体,将需要昂贵的人工智能模型。莫拉维克写道,“让电脑在智力测试或下象棋时表现出成人水平的表现相对容易,但在感知和移动方面,要让它们具备一岁孩子的能力则比较困难或不可能。”
从机器学习的角度来看,莫拉维克悖论非常适用于寻求在不同机器学习模型中泛化知识的转移学习。此外,莫拉维克悖论告诉我们,机器智能的一些最佳应用将是人类和算法的结合。 准确性悖论 与机器学习直接相关的是,准确性悖论指出,与直觉相反,准确性并不总是对预测模型的有效性进行分类的好指标。这对于一个令人困惑的表述是怎样的呢?准确性参数来源于不平衡的训练数据集。例如,在一个类别a的发生率占主导地位的数据集中,类别a在99%的情况下都能找到,那么依此预测每个案例类别a都有99%的准确率将是完全错误的。 理解准确性悖论的一个更简单的方法是在机器学习模型中找到精确性和召回率之间的平衡。在机器学习算法中,精度通常定义为测量你对正类的预测中有多少是有效的,它由(真阳性/真阳性+假阳性)表示。作为补充,召回率度量你的预测实际捕获积阳性的频率,它由(真阳性/真阳性+假阴性)表示。
在许多机器学习模型中,精确度和召回率之间的平衡可以得到更准确的度量。例如,在欺诈检测算法中,召回率是一个更重要的度量。抓住每一个可能的欺诈行为显然很重要,即使这意味着可能需要通过一些假阳性。另一方面,如果算法是为情绪分析而创建的,而你所需要的只是微博中所表达的情绪的高级概念,那么关注精度就是正确的方法。 哥德尔可学习性悖论 把最具争议的问题留到最后,这是今年早些时候发表在一篇研究论文中的一个最新悖论。这个悖论将机器学习模型的学习能力与最具争议的数学理论之一——哥德尔不完全性定理联系起来。 库尔特·哥德尔Kurt G?del是有史以来最聪明的数学家之一,他像前人一样突破了哲学、物理和数学的界限。1931年,哥德尔发表了他的两个不完全性定理,这两个定理实质上是说,有些命题不能用标准的数学语言证明为真或为假。换句话说,数学是一种不足以理解宇宙某些方面的语言。这些定理被称为哥德尔连续统假设。 在最近的一项研究中,以色列理工学院Israel Institute of Technology的人工智能研究人员将哥德尔连续统假设与机器学习模型的可学习性联系起来。在一个挑战所有常识的似是而非的陈述中,研究人员定义了一个可学习的界限的概念。本质上,研究人员继续证明,如果连续统假设是正确的,一个小样本就足以做出推断。但如果它是假的,那么没有一个有限的样本是足够的。他们用这种方法证明了可学习性问题等价于连续统假设。因此,可学习性问题也处于一种不确定的状态,只能通过选择公理体系来解决。 简单地说,研究中的数学证明表明人工智能问题服从哥德尔连续统假设,这意味着人工智能可能会有效地解决许多问题。尽管这一悖论在当今的现实世界人工智能问题中几乎没有应用,但在不久的将来,它将对该领域的发展至关重要。 在现实世界的机器学习问题中,悖论无处不在。你可以争辩说,因为算法没有常识的概念,它们可能不受统计悖论的影响。然而,考虑到大多数机器学习问题需要人类的分析和干预,并且是基于人类策划的数据集,我们将在相当长一段时间内存在于在一个充满悖论的宇宙中。 (全文完) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 作者:Jesus Rodriguez 翻译:区块链Robin
BTC:1Robin84SWtzSxnU1v8CE9rzQtcfUsGeN —- 编译者/作者:区块链研究员 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
数据科学家应该知道的五个悖论
2020-04-04 区块链研究员 来源:区块链网络






LOADING...
相关阅读:
- ?zgürDemirta?的以太坊预测是正确的2020-08-02
- 黑客发现Twitter黑客背后! 来自佛罗里达的一名少年(17岁)和他的两个2020-08-02
- 黑客发现Twitter黑客背后! 来自佛罗里达的一名少年(17岁)和他的两个2020-08-02
- 1万美元的比特币,你再也买不到了2020-08-02
- MΛNTRΛDΛO受邀参加金色财经区块链周郑州峰会掀开中原地区区块链产业2020-08-02