4月15日,Ultrain按2020年技术路线图的规划,顺利完成了“自适应动态组网”功能的发布,代码发布在Github的如下TAG: https://github.com/ultrain-os/ultrain-core-production/tree/4.0.0 我们今年的技术目标之一,是希望通过区块链技术,重点赋能充分竞争的行业,帮助其低成本建立互信的加盟制商业模式。 我们设想这样一个商业场景,一个省级餐饮联盟,在全省有二十几个餐饮品牌的1500家加盟店,他们希望在联盟内实现餐饮消费积分的互相兑换,让消费者在品牌内可以兑换积分,在二十几个品牌内也可以互相兑换使用。在传统的商业环境下,这种设想是很难建立的,因为积分平台一般是由盟主来建设和控制的,在传统的技术手段下,即使盟主如何表明自己公开透明,加盟企业也很难信任平台没有违背规则,自己偷偷增发积分,因为这是对盟主可以直接带来收益的行为,盟主在这里很难自证清白。 我们可以通过Ultrain区块链技术来解决这个问题,我们可以在1500家加盟店内部署1500个节点,每个加盟店自己提供一台电脑,在电脑上安装Ultrain区块链软件,就可以将这1500台电脑组织成一个Ultrain区块链网络,积分的发行、流转、兑换、消耗等行为数据都会直接记录到Ultrain区块链网络中,该数据会同时同步到这1500台电脑中,没有任何方法可以修改或删除这些积分的相关数据,通过这种方式,所有加盟店都可以信任这套积分体系并加入运营。 如果区块链技术可以支持这个商业场景,我们有多个技术点需要突破。比如电脑是由各个店家控制的,有些电脑可能会长期运行,有些电脑可能就是在店家上班时才会开启,下班后就会关闭,同时各个店家的上下班时间也不一样,所以电脑开启和关闭的时间也会不同;同时由于是在公网中运行,网络的状况也会时好时坏,会存在部分电脑突然网络状况恶化,无法链接到网络的情况。所以,我们面对的是一个动态电脑网络的情况,这个网络中随时都有电脑加入和退出,同时在线的电脑数量是不固定的。 在传统区块链的BFT共识协议中,如果网络中超过1/3的电脑都掉线和不在网络中,整个区块链网络就会瘫痪了。但在上述的商业场景中,这种情况很有可能出现,Ultrain的“自适应动态组网”技术有效的解决了这个问题。在Ultrain区块链网络由于各种原因其节点数量逐步减少的过程中,Ultrain网络可以动态适应这个过程,甚至在网络中超过1/3的电脑都掉线的情况下,也可以保持Ultrain网络一直长期稳定地运行,在断线的节点恢复上线以后,Ultrain网络也会自动将这些“复活”的节点接入到网络中,让其继续提供服务。 下面我们来具体介绍下Ultrain的“自适应动态组网”功能在技术上是如何设计的。 区块链是一种特殊的分布式数据库,由系统在委员会节点中按照一定共识算法产生记账节点,记录和修改链上信息,并同步到所有委员会。基于BFT的共识算法,都存在以下两个问题: l一定概率下选中了不在线的委员会成员作为记账节点,无法生产有效块。进而导致本轮记账过程出空块。 l当大量委员会成员逐渐掉线后,会导致无法完成BFT的共识算法,系统就会停滞在当前轮,无法继续进行。整个区块链网络就瘫痪了。 Ultrain针对共识的两个问题,提出一种基于离散心跳信号的解决方案。采用每一个被监控节点设置单独的监测时间,防止惊群效应。 自适应动态组网包括以下步骤: 1)区块链中所有有效委员会成员的数量为m,采用BFT的共识算法在区块链上在每个出块周期t内会产生一个数据块; 2)在区块链部署心跳监测智能合约,区块链中所有有效委员会成员必须在规定的时间间隔T内,发送该心跳监测智能合约中的签到交易,完成链上签到,之后抽取节点进行检查将没签到的有效委员会成员移除。 为每一组(一个)节点设置不同的检查点,可以有效的防范惊群效应带来的瞬间系统瘫痪。 抽取节点进行检查,将没签到的有效委员会成员移除,具体包括: A)将间隔时间T分成n个时间节点(slot,以下简称检查点),每个检查点的间隔为T/n; B)基于节点的关联性,将节点划分成为若干集合; C)随机从每个有效集合中抽取一个节点进行检查,形成本检查点的抽样集合; D)没有签到的,将被从有效委员会中移除; E)对于有异常节点的集合,将在接下来的检查点,增加抽样权重α; 步骤A)中,所述的n通过关联度δ确定,关联度δ的取值范围为0~1。 步骤B)中,基于节点的关联性,将节点划分成为若干集合,具体包括: a)将所有节点划分成为24个集合Ci,其中0≤i≤23; 对于区块链节点,是否能正常提供算力,跟时间有密切关系,因此,我们采用时区划分的方式,首先将所有节点划分成为24个集合,集合Ci其中(0≤i≤23); b)对于节点数不超过Min的集合统一向左归集,其中,Min设为总节点数的3%; 比如,集合Ci节点数少于Min,那么就将它们归集到Ci-1集合; c)删除归集后产生的空集合,得到有效集合; d)用一个二维特征属性来描述节点(X,Y),其中,X是所属时区的编号,Y是该节点的历史出块数; e)每个有效集合选出
个质心,
,其中,N(Ci)是集合Ci的节点数; f)节点(X,Y)和
个质心利用K-Means算法,求出K个节点簇,其中,
,完成节点划分成为若干集合; 利用K-Means算法,(X,Y)可根据具体网络特点设置,比如,对于时间敏感的网络可将X权重设置为99%,Y权重可设置为1%。 步骤E)中,这个检查点上被检查出问题的节点集合,根据其关联性,仍然存在异常节点的概率变高了,所以在接下来的抽样中,就增加权重α。 在Ultrain的这种方案中,这h个异常的委员会节点被心跳方法(合约)及时甄别出来,并移除委员会,那么有效委员会数量就变成m’= m-h。 每一轮共识选取记账节点时只会从有效委员会中选取,可以有效避开不在线的委员会。 同时该方案,临时将异常节点移除委员会,即使这部分节点参与了共识,也会被当做无效节点处理,杜绝了作恶的发生。 当委员会重新上线,发送该心跳方法后,系统将它加回备选委员会列表。可以继续参与共识。 Ultrain的这种方案将系统的委员会在线状态分为5种: 1、低风险状态,不在线节点少于5%; 2、中低风险状态,不在线节点5%-15%; 3、中风险状态,不在线节点15%-30%; 4、高风险状态,不在线节点 30%-33%; 5、宕机状态超过1/3节点不在线。 与现有技术相比,Ultrain的这种方案具有如下优点: 现有技术中的普通的心跳监控,一般有一个统一的监控周期T,时间到了,就检测哪些节点未及时发送心跳消息。这会带来一个潜在的风险,就是在某一个周期超过阈值的节点同时异常,这种现象会绕过心跳监控系统,给系统带来灾难性的打击。而这种情况的概率,跟监控周期T成正比。而Ultrain的这种方案中,为每一组(一个)节点设置不同的检查点,可以有效的防范惊群效应带来的瞬间系统瘫痪。 接下来,我们定量证明该方案的显著优于现有的心跳监控。 具体地,假设总节点集合M = 96,节点间相互独立,每个节点发生异常的概率p= 10%,超过f=1/3 节点同时发生异常的概率P = p^(m*f)其实是很低的。 但是完全相互独立是理论上的,现实中,很多节点都有相关性。网络方面,操作者的一些习惯。比如有些节点会在夜间被关掉。这就大大增加了区块链的不稳定性。 我们进一步简化模型,将M=96根据步骤k-means算法,组成K群组,组内节点具有关联性,相关系数 δ = 1(即关联度δ=1),群组间相互独立。 我们假设在某个时间,系统多个节点宕机,系统进入高风险状态,随时都会宕机,而且出空块的概率接近1/3,系统处于低可用状态,这个时候,通过比较系统脱离高风险状态的时间来证明本方案的优势。 根据我们上面对节点群组模型的定义,假设两个群组的节点宕机,宕机的集合B,任意bi∈B不在线,|B|= 32,B∈M我们需要检测出超过y =5个节点才能使系统脱离高风险区域。 我们将周期T分成M/K个检查点,每个检查点,随机抽取K节点簇中抽取一个节点来检查心跳方法的打卡情况。 在第一个检查点随机从步骤2中用k-means算法求得的K个节点簇中抽取一个节点组成集合H,其中H∈m则若|H∩B|≥5,就是集合H和B的交集数量超过5个,意味着,在第一个检查点,就检测到了超过5个宕机节点,使得系统脱离高风险区域。这个事件发生的概率:
其中,P(|H∩B|≥5)表示集合H和B的交集数量超过5个的概率,
表示从总集合M抽取k个节点的组合种类,
表示从B集合也就是出故障节点集合,元素中取i个元素的种类其中(0≤i≤4),
从M-B的集合中抽取k-i个节点组合种类,通过递归法逐项求得在第n(1≤n≤6)个检查点以前能检测到超过5个宕机节点的概率如表1所示:
表1 分时随机监测与固定时间监测对比 从数据分析,可以看出在T/6 的时候系统由67.9%的概率从高危状态恢复,而在T/3时候系统从高危状态恢复的概率超过99.9%大大优于固定时间监测的算法。 采用分时随机监测,从高危状态恢复的期望时间从T变成0.22T。 显然,如果我们可以将T分成更多的时间段,期望时间可以更加的迁移,如图1所示。
图1 期望恢复时间 可以看出期望恢复时间确实是随检测密度增加而减少,根据不同系统需求,可以设置不同的参数。 使用该方案后,区块链共识算法就会更加健壮。 当有部分节点开始逐渐离线时,它们就会停止发送心跳交易,区块链系统会及时感知到这一变化,将异常委员会成员从委员会中剥离。 BFT的共识算法对少量委员会成员离线是有容错机制的。但是当离线节点超过委员会的1/3后,系统就无法达成BFT的共识,进而瘫痪。本方案会及时将失效的委员会成员移出委员会来修复BFT系统,使得整个共识系统可以持续有效运行。 本文来源:Ultrain超脑信任计算 —- 编译者/作者:Ultrain超脑信任计算 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
技术突破 | 提高区块链共识效率的自适应动态组网方法
2020-04-30 Ultrain超脑信任计算 来源:火星财经




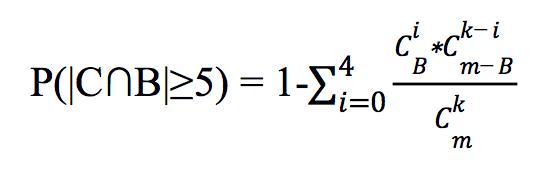





LOADING...
相关阅读:
- 以太坊成功突破400美元2020-08-02
- 区块链上的鲜血:令牌化可以使捐赠更有效2020-08-02
- 昕雨论币:8.2以太坊晚间盘面行情分析与操作策略、直观盘面全局趋势2020-08-02
- ?zgürDemirta?的以太坊预测是正确的2020-08-02
- 小贾言币:以太坊刷2年新高怒涨2020-08-02