拜占庭断层(Byzantine Fault)
共识是分布式系统中所有节点就单个状态达成一致或做出相同决策的过程。共识算法是过程的一组协议或规则。
共识是复杂的,因为它基本上是许多问题,如果包含各种约束,则更加复杂。最困难的约束之一是拜占庭错误。
拜占庭故障表示可能存在不遵守规则甚至故意违反以防止达成共识的异常或恶意节点。这些节点可能会这样做,因为它们被破坏或被黑客占用。尽管这个问题从古希腊城市或罗马行省的名称「拜占庭」的名称来看似乎是一个非常古老的问题,但直到80年代人们才开始研究拜占庭断层。
1982 年发表的早期论文?,对拜占庭断层的描述如下图。

拜占庭问题
拜占庭军队的几个师在敌人周围建立了营地。每个师的将军都必须做出进攻或撤退的决定。他们希望做出同样的决定,以避免出现一些师进攻,而另一些师撤退的麻烦情况。为了调整决定,拜占庭将军可以派使者将他的意图传达给其他将军。但问题是将军之间可能有叛徒。这些叛徒会干扰消息交流,以防止所有正常的将军得出相同的结论。例如,如果⑥将军是叛徒,他可能会向①将军发送进攻意图,而将撤退意图发送给将军②和将军⑤,以防止达成共识。

叛徒将军试图扰乱共识。
如果没有叛徒,简单的多数规则总能引导将军们达成共识。换句话说,每个将军收集所有其他将军的意图,并按照包括他自己在内的一半以上将军的意图得出结论。如果所有将军都被一分为二,则可以应用默认操作。
但随着叛徒的可能性,问题变得复杂。如果6位将军中只有一个叛徒,这个多数规则是否也可以让其他5位将军一直达成共识?或者,是否有任何其他规则可以保证共识? 6个将军中2个叛徒怎么样?
在上述情况下,如果一个共识算法可以使所有忠诚(非叛徒)将军做出相同的决定,则该算法被称为拜占庭容错。拜占庭容错算法的特征或要求是拜占庭容错或简称 BFT。让我们用一个最简单的案例进行更详细的解释,以便更清楚地理解。
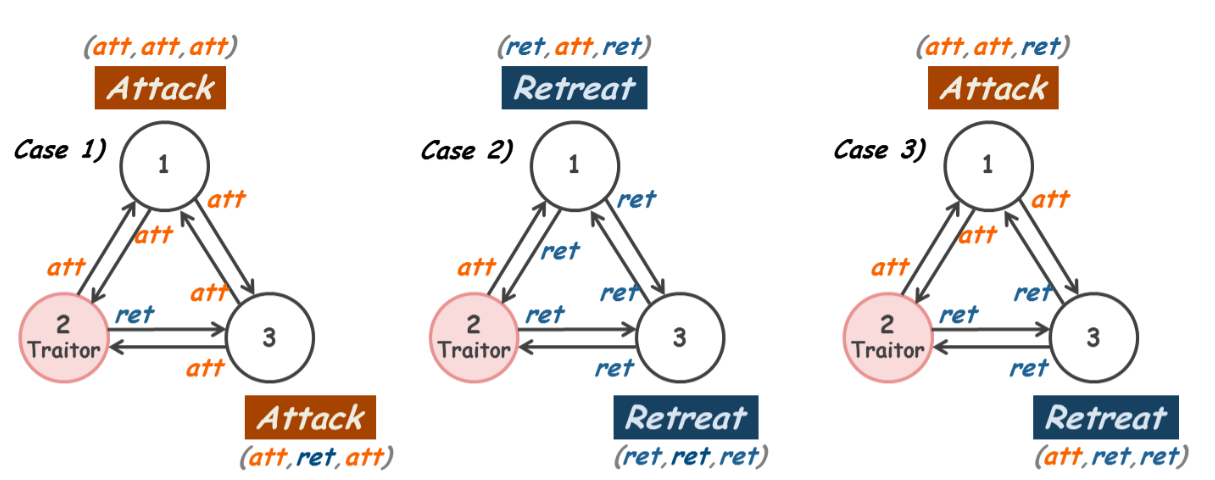
最简单的案例:2名忠将和1名叛徒
假设一共有3个将军,只有一个是叛徒。当然没有人知道谁是叛徒。共识算法是一个简单的多数规则。
叛徒总是向其他2位将军发送相反的意图,以阻碍共识。从上图中的案例(1)和案例(2)可以看出,如果两个忠诚的将军有相同的意图,无论叛徒的干扰如何,他们都会得出相同的结论。但是像情况(3)一样,如果两个忠诚的将领有不同的意图,最后一个会进攻,另一个会撤退。在情况(3)中共识将被打破,因此多数规则对于这 2 个忠诚的将军和 1 个叛徒来说不是拜占庭容错的。那么,针对这种情况的拜占庭容错共识算法是什么?
从理论上证明,如果不使用消息签名,则不存在针对 3 名将军和 1 名叛徒的拜占庭容错算法?。
在共识中,除了拜占庭错误之外,还有各种限制。最常见的约束是是否保证消息传递,消息是否签名,以及网络是否完全连接。
如果在某个延迟限制内保证交付,则网络被称为同步(sync.),如果由于通信故障或过载而可能丢失消息,则网络被称为异步(async.)。当然,使异步网络具有拜占庭容错能力要比同步网络困难得多。
如果应用消息签名?,恶意节点在中继来自其他节点的消息时无法更改消息,尽管它自己的消息仍然可以被操纵。因此,通过消息签名,可以更轻松地设计拜占庭容错算法。但是,构建可靠的消息签名系统也需要相当大的成本和精力。
[1] L. Lamport、R. Shostak 和 M. Pease,“拜占庭将军问题”,1982
[2] 数字签名
3m + 1 处理器算法
保证拜占庭容错的通用算法的第一个成果是1980年出现的「3m+1处理器算法」。
论文?首先证明,对于一个有m个故障节点的同步网络,如果网络的节点总数等于或小于3m,则不存在拜占庭容错共识算法。换句话说,前提是有超过 3m + 1 个节点。

例如,如果 3 个节点中有 1 个故障节点,则不存在拜占庭容错算法。当预期有 1 个故障节点时,网络应至少有 4 个(3m + 1,m = 1)个节点,如上图左起第二个。如果节点更脆弱并且可以同时存在 2 个故障节点,则网络应该至少有 7(3m + 1,m = 2)个节点用于拜占庭容错,如上图最后一个。
那么,什么是拜占庭容错算法,在保证3m+1约束的情况下。在详细介绍之前,我们先研究一个简单的消息传递符号。

4节点网络的消息传递
上图显示了一个简单的 4 节点网络的消息传递。最多可以有 5 条不同的路径将消息从节点 ① 传递到节点 ④,包括中继。但是不包括消息访问中间节点超过 2 次的重复中继。
5条路径包括1条直接下发路径、2条间接下发路径1个中继、2个路径2个中继。
这些情况如下表示

例如,v:1:3:2:4表示消息由节点①发送到节点③,由节点③中继到节点②,再由节点②中继,最后到达节点④。

3m + 1 处理器算法
上面的说法是被称为3m+1处理器算法的共识算法。该算法为拜占庭容错强制执行足够的中继。
更准确地说,对于最多可能有 m 个故障节点并因此包含至少 3m + 1 个节点的网络,应该将每个消息中继 m 次。并且每个节点必须代表考虑 m 次中继的多数规则来决定其他节点的意图。
如果网络有 4 个节点 (m = 1) 来覆盖最多 1 个故障节点,则每个节点必须在收集其他 3 个节点的直接消息 (OM(1)) 和 1 次中继消息 (OM(0) ))。对于 m = 1,2 次中继也是可能的,但根据算法,1 次中继就足够了。
对于 m = 2,网络有 7 个节点来克服 2 个故障节点,每个节点应该收集直接消息(OM(2))、1 次中继消息(OM(1))和 2 次中继消息(OM(0) ))。 7个节点,最多可以进行5次中继,但是2次中继就足够了。
所以,当推广到m个故障节点时,至少3m+1个节点中的每个正常节点必须收集直接传递的消息(OM(m)),1次中继(OM(m-1)),2次中继(OM( M-2)),依此类推,直到转发了 m 次 (OM(0))。

3m + 1 处理器算法的递归
你可能会注意到,在中继消息时,消息不会再次发送到之前已经通过的节点。例如,在7节点网络中,节点①的消息经过节点②中继后到达节点③,将不会再发送到节点②或节点①。这条消息会从④到⑦发送到其他节点。
工作证明
在上面解释的 3m + 1 处理器算法或 pBFT 中,节点协作克服拜占庭故障。为了协作解决损坏或被黑客攻击的节点的干扰,算法对节点数量有限制并且需要足够的通信,这限制了可扩展性。
3m + 1 处理器算法的复杂度为 O(n?),pBFT 的复杂度为 O(n?)。
工作量证明?(PoW)算法采用完全不同的方法。在 PoW 网络中,每个节点都在竞争而不是协作。成功解决一个极难解决但很容易验证的数学难题的节点将在当时为整个网络做出决定。在解决了一个难题并且解决方案在整个网络中传播后,下一个难题的竞争就开始了。
有几种类型的此类难题,包括哈希计算和大整数的素因数分解?。没有特殊的公式或技术可以更快地解决此类难题。只有简单的反复试验和错误?才是有效的策略。
因此,节点解决难题的机会完全是概率性的。概率完全取决于节点的计算能力。如果计算能力在节点之间足够分散,那么特定的一个或多个节点实际上是不可能统治 PoW 网络的。
比特币和以太坊等公共区块链网络,由于该网络是开放的,任何人都可以与自己的节点作为对等体加入,因此在很大程度上抑制了计算能力的集中。

工作量证明过程
对于比特币和以太坊,难题在于找到一个随机数,该随机数满足与随机数结合的块头哈希的非常特定条件。
作为用于理解的一个简单(非真实)示例,条件表示散列应以 4 个前导零开头。下面的句子更简洁明了地表达了条件或难题——SHA-256 是流行的哈希函数之一,数据表示块头
Find nonce for SHA-256(data + nonce) to Start with '0000'
哈希函数?是一种将任意大小的数据转换为完全不同且不可预测值的固定大小数据的函数。哈希函数具有一些重要且独特的特性。第一个也是最重要的是功能是不可逆的。更正式地说,哈希函数没有反函数。
例如,“Hello, world!”的 SHA-256? 哈希值简单明了。是“0x315f5bdb76d0...”,但是对于“0x315f5bdb76d0...”的哈希值是“Hello, world!”无法计算逆SHA-256使用任何公式或特殊技术。
SHA-256(\"Hello, world!\") = \"0x315f5bdb76d0…\" # easy
SHA-256??(\"0x315f5bdb76d0…\") = \"Hello, world!\" # no formula
第二个特点是,即使输入变化很小,散列函数也会大量改变输出(散列值)。换句话说,哈希函数非常动态地扩散输入。
你可以在下表中看到这一点。在表中,输入值与“Hello, world!”略有不同。到“你好,世界!0”,“你好,世界!1”,“你好,世界!2”,等等。但是它们的哈希值是完全不同的。你永远无法从“Hello, world!0”、“Hello, world!2”或其他类似输入的哈希值中猜测或计算“Hello, world!1”的哈希值。

查找随机数示例
如果需要找到一个随机数,它会在附加在“Hello, world!”之后产生以 4 个前导零(“0x0000”)开头的哈希值。 ——就像上表最后一行的“Hello, world!4250”一样,没有比从“Hello, world!0”到“Hello, world!4250”的简单顺序试验更有效的特殊方式或方法了。
以太坊使用的具体 PoW 算法是 Ethash?。 Ethash 使用 Keccak-256 作为哈希函数。 Ethash 的难题是找到一个随机数,使区块头的 Keccak-256 哈希值和该随机数小于指定值。
在比特币或以太坊中,每笔交易都经过数字签名,因此故障或叛徒节点无法操纵交易。区块很容易验证,但极难挖掘,因此恶意节点无法传播无效区块。像这样,同时使用 PoW 和数字签名,比特币和以太坊可以实现拜占庭容错。
因为 PoW 是基于竞争而不是公司运作的,所以复杂性与节点数量无关。复杂性很大程度上取决于谜题的难度。因此,对于包含数百或数千个节点的大型网络,PoW 似乎比 pBFT 等基于公司的共识算法更有利。但是 PoW 也有致命的问题。最著名的一个是由于激烈的竞争而造成的巨大能源浪费,另一个重要的问题是下面详细解释的最终性问题。
终结性问题
概括地说,成功的解谜被称为 PoW 网络中的挖矿。挖矿意味着创建一个新块并奖励矿工。大量节点激烈竞争以获得奖励。查看挖矿规则的细节,哈希计算除了要添加的交易和随机数之外,还包括最后一个区块的哈希值。它用于维护区块链的线性或一维。这使得破坏区块链的完整性并防止区块链中的冲突状态变得更加困难。
在大多数情况下,挖矿的间隔足以保持区块链的线性。但是无论难度增加多少,几乎都可以同时进行挖矿,因为挖矿本质上是概率性的。虽然验证非常简单,但将挖矿出的区块传播到世界各地的所有节点需要时间。因此,同时挖矿使整个网络有点不均匀。
像下面的例子。如果两个遥远的节点 P 和 Q 成功挖出一个区块——每个区块中的区块 B(m) 和区块 B(n)——几乎同时,在时间不足以传播 B(m) 和 B(n) 的时间内在整个网络中,P 周围的节点将 B(m) 作为最后一个块,Q 周围的节点将 B(m) 作为最后一个块。与 P 和 Q 距离相近的节点无法区分实际首先开采的是哪个区块。

两个不同的节点可能几乎同时成功挖矿。
B(m) 和 B(n) 都基于相同的前一个块。换句话说,它们包含与前一个区块头相同的哈希值。因此,前一个块称为父块。
节点不断尝试挖掘下一个区块以获得奖励。一些最先收到 B(m) 的节点会根据 B(m) 挑战下一个块,但之前收到 B(n) 的其他节点会根据 B(n) 挑战下一个块。尽管在大多数情况下,由于困难,成功的挖矿以足够的时间间隔发生,但下一次挖矿几乎同时发生的可能性非常低。在这些情况下,挖掘出的区块可以有不同的父区块。例如,第二个同步块之一基于 B(m),另一个基于 B(n),如下例图像所示。
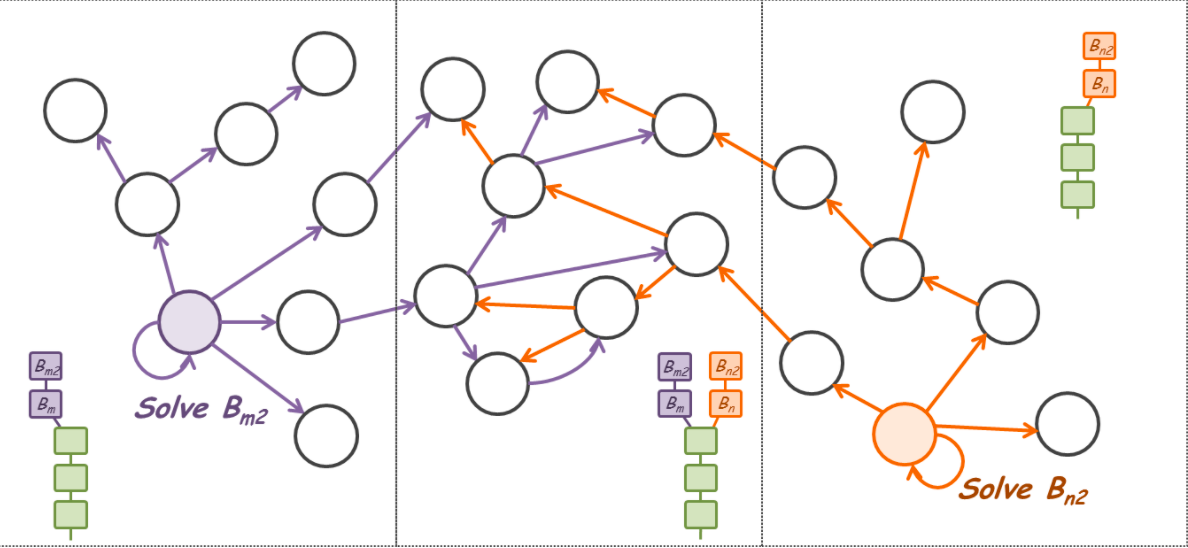
下一次,另外 2 个不同的矿工可能会再次几乎同时成功挖矿。
你可以看到整个链不再是线性的,尽管之前没有违反 PoW 规则。这称为分叉,从分叉点开始的每个线性(线性连接)部分称为分支。在上面的例子中,有 2 个分支。一个分支是 B(m) 后跟 B(m2),另一个分支是 B(n) 后跟 B(n2)。
由于挖矿竞争激烈且网络不统一,之前的异常(但不违法)情况可能会进一步延续。换句话说,2 个分支更像 B(m)-B(m2)-B(m3)-B(m4) 和 B(n)-B(n2)-B(n3)-B(n4)。甚至可能出现另一个分支。
但是,最终只有一个分支会存活下来,因为挖矿真的很困难,而且所有这些都是概率性的。还有另一种称为最长链规则的机制,它强制在分叉情况下选择最长的分支。一旦同时发生的分支之一开始快速增长,最长的规则将只加速一个分支的生存。

最终,分叉后只有一个分支会存活下来。
虽然链条长期保持线性,但同时可能会出现一个严重的问题,称为终结性问题。最终性问题是由于上述分叉而导致成功挖掘的交易或区块变得无效或稍后被取消的情况。它不是由违反 PoW 引起的。这是 PoW 的一个内在方面。
下图描述了一个典型的终结性问题过程。它显示了区块链随着时间的推移而增长。在②处,包含 tx(b) 的区块 B(n) 被成功挖掘。但几乎同时,另一个不是 B(n) 子节点的块 B(m) 也被挖掘出来,形成了一个分叉 (③)。尽管两个分支一直一起增长,但毕竟源自 B(m) 的一个分支幸存下来,使块 B(n) 和交易 tx(b) 失效,就像 ⑥。这意味着完全提交一次的事务可以在以后回滚。从数据持久性系统的角度来看,这是一个重大缺陷。

为了解决最终性问题,我们应该等待一段时间,即使在挖矿之后,包括我们的交易在内的区块也会进一步增长。通常,比特币需要 6 个区块,以太坊需要 12 个区块。当然,这些数字并不能保证完美无缺。
目前以太坊的区块时间约为 13 秒。但最终性问题使得确认交易的实际时间为 2.6 分钟而不是 13 秒。
一个巨大的矿工可以利用最终性问题来破坏区块链的完整性和信任。如果他或她拥有超过 50% 的整个挖矿能力,他或她可以使非常重要或昂贵的交易无效以赚取利润或达到邪恶目的。这被称为「51% 攻击」。
尽管在数百个独立活跃的矿工中占据超过 50% 的算力几乎被认为是不可能的,但实际上存在 51% 攻击的线程?。以太坊类(ETC)在 2019 年 1 月遭到攻击?,比特币黄金(BTG)在 2020 年 1 月?。
为了解决最终性问题,以太坊开发了一种名为 Casper FFG 的新共识算法,它是以太坊 2.0 的关键特性之一。
[1] 工作量证明
[2] 素数分解
[3] 试错
[4] 哈希函数
[5] SHA-256
[6] Ethash 规范
[7] 什么是 51% 攻击?
[8] ETC 51 % 攻击——发生了什么以及如何阻止它(2019 年 1 月 14 日)
[9] 比特币黄金区块链遭到 51% 攻击,导致 7 万美元双花(20 年 1 月 27 日)
Casper FFG
Casper FFG 是一种 PoS(Proof-of-Stake)共识算法,具有一些独特的功能,有望解决或显着改善最终性问题。它由 Vitalik Buterin 和 Virgil Griffith 于 2017 年首次提出?。

首先,Casper FFG 是一种部分共识算法,只承担最终性协议。 Casper FFG 不包含任何创建或确认块的规则。它定义了一个协议,以在分叉情况下更快地确定多个分支之间的真正最终块。它可以应用于其他共识算法,例如 PoW。因此,Casper FFG 被归类为覆盖算法。
其次,Casper FFG 本身是一种 PoS(Proof-of-Stake)算法,它期望选定的节点运行。与任何节点都可以参与挖矿的 PoW 网络不同,在 PoS 网络中,只有一些拥有某些权益的特殊节点才能加入共识以确定区块之类的东西。在 Casper FFG 中,这些节点称为验证器。
第三,Casper FFG 定义了激励规则和惩罚规则。包括 pBFT 在内的其他 PoS 算法通常没有惩罚规则。所以即使一些恶意节点试图扰乱共识,也没有有效的方法来阻止它们。 「无利害关系」? 是 PoS 算法最著名的问题之一。但是,在 Casper FFG 的情况下,不利用任何利害关系的验证者将受到惩罚并失去所有的股份。
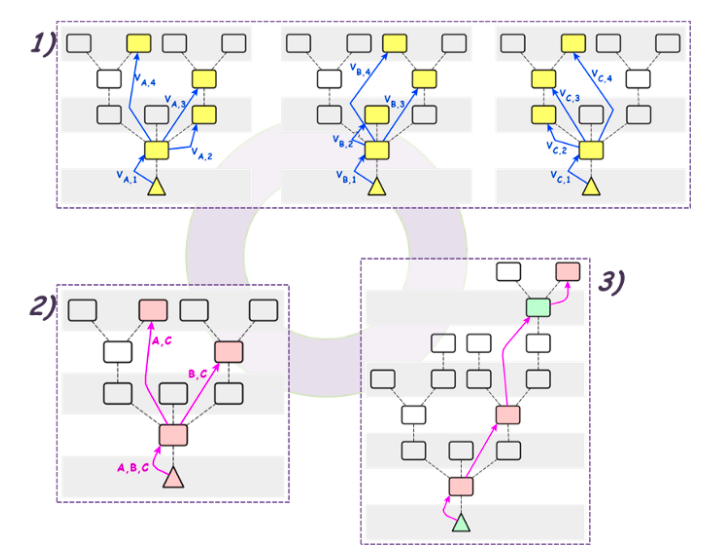
Casper FFG 流程 — 1) 投票,2) 合理,3) 最终确定
与 pBFT 或通常的 PoS 算法一样,Casper FFG 以固定的时间安排运行轮次。在每一轮中,所有验证者都应遵循 2 条严格的规则在每一轮中投票。如果验证者违反规则一次,它将失去其权益并被驱逐出验证者。因此,这些规则称为斜线条件。
如果一个区块在一轮中收到超过 2/3 验证者的投票,则称该区块是合理的。对齐的块仍然可以分叉,因此没有最终确定。但是如果两个连续的块是合理的,那么这两个的父块最终会被敲定。
补充一些细节,因为斜线条件禁止跨越投票,在相邻的两个区块获得投票后,最多有 1/3 的验证者可以在后面的轮次中按照规则对父区块以下的任何区块进行投票。因此,除非另外 1/3 验证者违反斜线条件而失去所有权益,否则父区块将是所有后来的合理投票的祖先。
由于惩罚规则(斜线条件),Casper FFG 有望促进更紧密的合作,并导致比最长链规则更快、更有效的终结。
Casper FFG 是 Beacon 链的治理算法,是以太坊 2.0? 阶段 0? 的最高特征。
[1] Vitalik Buterin 和 Virgil Griffith,“Casper the Friendly Finality Gadget”,2017 年
[2] 没有任何利害关系的问题——一团糟!
[3] 以太坊 2.0 信息
[4] 验证:在 eth2 #0 上质押
[5] Casper FFG 解释
[6] Vitalik Buterin 和 Virgil Griffith,“Casper the Friendly Finality Gadget, Ver. 4”, 2019
原文作者:Sangmoon Oh
原文链接:Basic Consensus Algorithms, Explained
—-
编译者/作者:洁sir
玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。