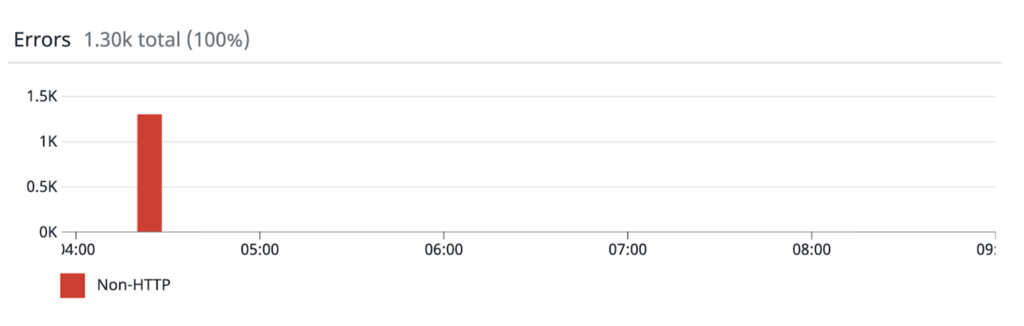
乔丹·锡金(Jordan Sitkin) 1月29日(星期五)太平洋标准时间凌晨4:25至9:31之间,api.coinbase.com发生了故障。 在这段时间内,许多用户在尝试使用Coinbase应用程序时遇到错误,并且间歇性地提供了加密购买,出售和交易功能。 在pro.coinbase.com上进行交易的权限不受影响。 这篇文章将详细描述中断,解释造成中断的原因,并描述我们为防止类似故障而进行的更改。 断电 一组应召集的工程师聚集在一起后,召集了许多端点的高错误率。 它很快被诊断为Redis集群的问题,该集群用于存储货币兑换的即期汇率。 这些即期汇率用于估算货币之间的转换,这使它成为一系列功能的关键路径,例如以当地货币显示投资组合的价值。 此Redis群集上的CPU负载突然达到100%,并导致多个API端点和后台作业失败。 我们立即采取行动来减少此群集上的负载,以便它可以恢复。 我们的监控表明,该群集上的大部分负载来自后台作业,因此我们开始禁用它们,并期望查询吞吐量下降。 在禁用作业几个周期之后,群集上的负载仍然很高,因此尝试进行群集故障转移以查看故障是否是由于硬件问题引起的。 这也没有效果。 我们还无法部署旨在缓解此问题的代码更改,因为运行状况不佳的Redis集群阻止了新应用程序服务器的启动。 垂直扩展群集的尝试也未能降低CPU压力。 我们最终选择提供一个新的,更大的Redis集群来替换过载的集群。 一旦启动,我们就为其进行了全新的应用程序部署,并最终为我们的客户恢复了服务。 但是,目前仍未回答几个问题,促使我们深入研究并发现真正的根本原因。 根本原因分析 停电以来的几天里,我们对第一分钟发生的事情进行了清晰的描绘。 00:00s — Memcached节点重启。此Memcached部署在存储失败的Redis群集中的汇率的键之前提供了一个只读缓存。 在客户端将查询转移到另一个Memcached群集成员时,重新启动对应于缓存未命中的短暂高峰。 这并非史无前例,在这种情况下,Memcached客户端可以按预期快速恢复。
2. 00:02s —并发Redis查询峰值,连接池填满。由于Memcached节点重新启动而导致的同步缓存未命中,导致对Redis集群中存储的基础数据的查询异常。 并发查询数量的增加要求为它们提供服务的Redis连接数量增加50倍。
3. 00:07s —我们看到大量的Redis客户端超时错误。连接的突然涌入导致Redis引擎速度降低。 CPU利用率跃升至100%,并且在1秒钟的超时时间内停止了对查询的响应。 此时,我们的价格数据API端点的错误率约为90%。 这些超时使memcached无法补充其缓存,因此从那时起,此Redis群集上的负载仍然很高。
4. 00:13s — CDN上所有公共价格数据的5秒缓存TTL过期。通常,由于有了CDN缓存,这些端点在应用程序上的负载是稳定的。 在此期间,由于CDN开始将请求转发至应用,以补充其对所有资产价格数据的缓存,因此它飙升至正常交易量的5倍。 由于这些端点上的错误率达到90%,因此无法成功刷新绝大多数键的缓存。 由于Memcached遗漏,应用程序代码落入Redis来加载此数据,这进一步增加了已经超载的群集的负载。
此时,Redis群集正在接收查询吞吐量,其吞吐量是其正常负载的许多倍,并且由于Redis客户端超时和连接失败,其上方的缓存层(Memcached和CDN)无法进行补充。 任何依赖汇率数据的请求均失败,因此用户无法访问我们网站上的关键功能。 尽管多次尝试减少负载,但高速缓存未命中和客户端超时的周期仍使Redis群集在中断期间过载。 展望未来 事后看来,我们已经确定了监控中的一些盲点,这些盲点使我们无法快速了解故障。 我们的客户端Redis监控不包括超时查询。这使我们无法看到应用程序正在重载Redis,因为我们只查看成功的调用,而该调用在中断期间会减少。我们的服务器端Redis监视不包括失败的呼叫。这造成了一个令人困惑的仪表板,该仪表板显示网络活动急剧增加,但没有明显的查询活动。 我们的指标来自Redis INFO命令统计信息输出,并且不包括fail_calls或rejected_calls。仅在事件发生后发现Memcached节点重新启动因为此信息没有出现在我们的任何仪表板上。此外,我们的应用程序的配置方式允许最初的小故障级联成为全面的中断。 客户端连接池几乎立即增长到50倍,从而使Redis有了新的连接。为了解决这个问题,我们调整了连接池的大小,使其具有更大的最小值和合理的最大值。Redis群集配置不足。我们已将其替换为大小合适的集群,并审核了其余集群以确保正确缩放规模。我们没有在该群集上使用只读副本。我们正在探索Redis二级读取的更广泛使用,以更好地扩展此和类似用例。另一个重要的观察结果是,我们API某个区域的中断能够中断所有API的服务。 我们目前正在努力将我们的整体应用程序服务器分解为单独的服务,以防止此类中断的发生。 将API的这一部分放入一个可单独扩展的单元中,可以使我们与其他问题隔离开来,并防止其破坏其他功能。 我们非常重视基础架构的正常运行时间和性能,我们正在努力支持选择Coinbase来管理其加密货币的数百万客户。 如果您有兴趣解决此处介绍的扩展挑战,跟我们一起工作。 事件发生后的事态:2021年1月29日最初发布在The Coinbase Blog on Medium上,人们通过突出并响应这个故事来继续对话。 >>在Coinbase上查看 加入我们的电报 在推特上关注我们 在Facebook上关注我们 帖子 [Coinbase] 事件发生后的事态:2021年1月29日首次出现在AZCoin新闻上。
—- 原文链接:https://azcoinnews.com/coinbase-incident-post-mortem-january-29-2021.html 原文作者:Coinbase News 编译者/作者:wanbizu AI 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
[Coinbase] 事件发生后的事态:2021年1月29日
2021-02-06 wanbizu AI 来源:区块链网络

 Memcached客户端错误
Memcached客户端错误 Redis连接数
Redis连接数 Redis客户端超时错误
Redis客户端超时错误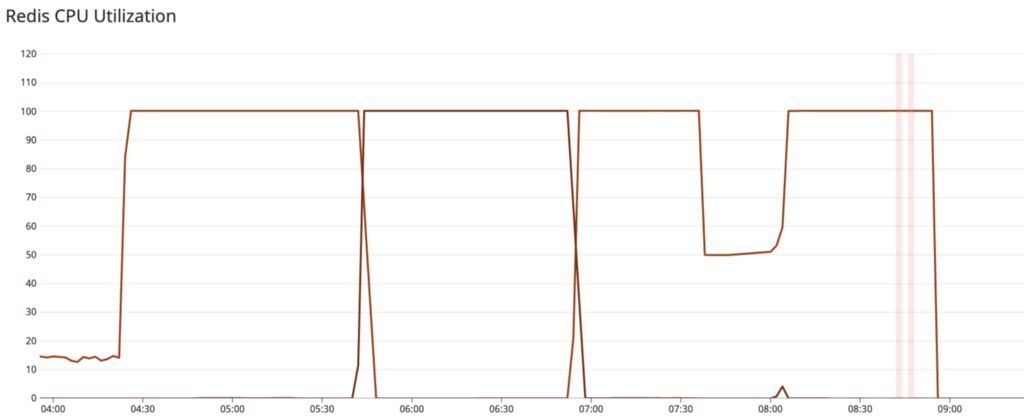
 CDN响应码
CDN响应码

LOADING...
相关阅读:
- Twitter首席执行官Jack Dorsey设立了比特币全节点2021-02-06
- MMMDEFI(MDF)智能合约_首页2021-02-06
- ADA达到三年新高的三大增长催化剂2021-02-05
- 11亿美元:比特币矿工报告今年开局成功2021-02-05
- 比特币超过黄金成为美国第四大最具吸引力的投资2021-02-05