| 科普 | 叔块验证与网络安全性
本文是讲解我在 go-ethereum(Geth)客户端中发现的 Bug 系列的第二篇。如果你还不了解它,请看第一篇。 这篇文章要讲的 bug 位于 Geth 客户端的状态下载器内,它可以用来欺骗下载器,使之不能与主网正确同步。攻击者可以利用这个 bug 给以太坊区块链设置陷阱、任意触发硬分叉。 同步 当你想运行一个以太坊节点的时候,首先必须同步上整个网络,即,下载和计算构建最新区块时刻的区块链状态所需的所有数据。根据用户自身的需要,同步方式可以在安全性和速度之间有所取舍,所以(在撰文之时) Geth 支持两种同步模式:完全同步和快速同步。 顾名思义,完全同步就是独立地执行完对以太坊区块链的整个同步过程。这就意味着,你的 Geth 节点会下载和验证每个区块的工作量证明(PoW),此外,它还会计算区块内的每一条事务;由此,节点可以在本地生成区块链的最新状态,而无需信任其它节点。这种模式更安全,但速度上有很大牺牲。Geth 的完全同步可能要花几天乃至几周不等的时间。 但是,有些用户可能不想等上几周。也许他们的时间很紧,又或者,他们并不觉得这种牺牲是值得的。因此,Geth 提供了一个模式:在近期的某个区块(称为 “pivot 区块”)之前的所有链数据,都用更快的方法来同步,只有 pivot 区块之后的区块链,才使用更慢的完全同步算法。在快速同步模式中,Geth 会下载区块,但仅随机选取一些区块来验证工作量证明,而不是每个区块都验证;而且,它也将不再自己执行事务,而是从网络中的其它节点处直接下载状态树,以此获得最终的区块链状态。 当然,Geth 也不会盲目相信其他节点发回的状态树数据,因为一个恶意的节点也可以声称某个账户只有一点点钱(但实际有很多)。要理解 Geth 如何能辨别收到的数据正确与否,我们先要理解默克尔帕特里夏树(Merkle-Patricia trie)。 默克尔帕特里夏树 默克尔帕特里夏树(MPT)是 Geth 客户端中的一种关键数据结构,它是默克尔树和帕特里夏树两者的结合。 简而言之,帕特里夏树会基于数据的前缀将数据存到一个树状结构中。相较于其它技术(如哈希表,hashmap)来说,帕特里夏树本身非常适合存储相似的数据,尽管在速度上可能有所牺牲。下面来看看,多个以r开头的单词是如何存到一棵帕特里夏树里的。
接着来说说默克尔树。在一棵默克尔树上,每个叶节点是数据的哈希值,每个非叶节点是它的两个子节点的哈希值。如果用户知道了默克尔树的默克尔根(即,顶端哈希值),并且想要确认某个数据是否存储在这棵树里,他只需要用到这棵树上的一条路径,这条路径所涉及的节点数量只跟叶节点数量的对数(注意不是叶节点数量)成正比。如下图所示,假设用户要证明L2存储在这棵树里,他只需提供Hash 0-0和Hash 1。接着,验证者生成Hash 0-1、Hash 0和Top Hash,再将Top Hash与其所预期的默克尔根进行比较。
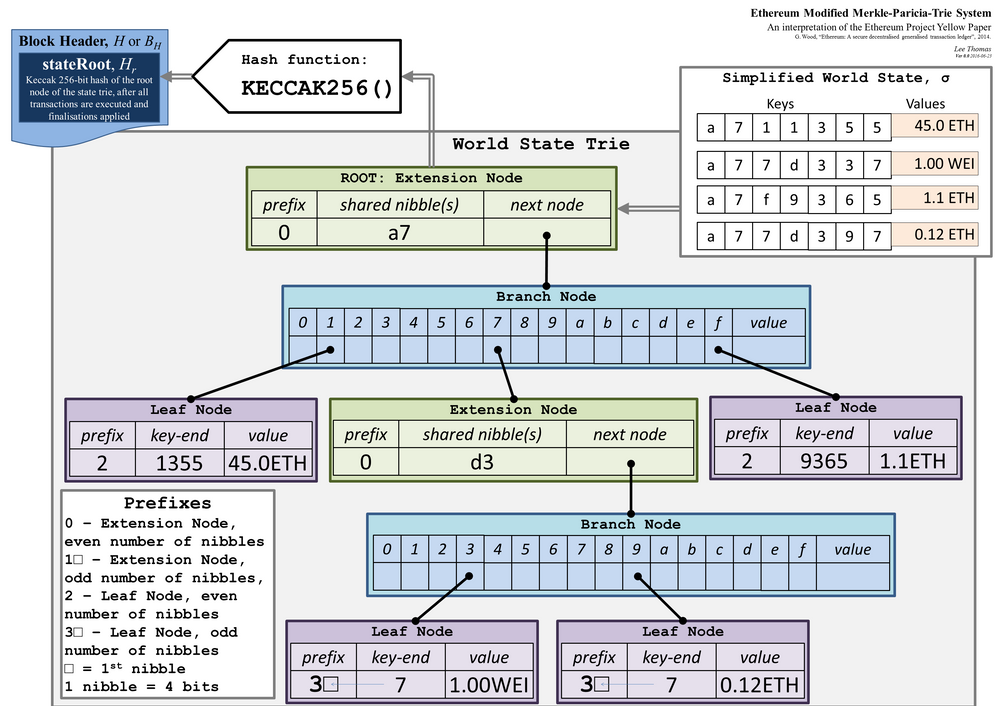
默克尔帕特里夏树将帕特里夏树基于前缀的存储结构与默克尔树相结合,创造出了一种新的数据结构,不仅支持密码学验证方式,而且还能保持良好的运行时性能。 在默克尔帕特里夏树中,键和值都是任意的字节串。要想获得一个键的值,我们首先要将这个键转换成一个十六进制字符序列,即,将每个字节变成两个十六进制字符。然后,我们要先根据序列中的第一个字符,向根节点查询下一个节点是什么;得到此子节点后,再根据第二个字符向下查询节点,依次类推,直至找到最后一个节点,获得最后一个字符。 在下面这个例子中,我们可以看到默克尔帕特里夏树实际上包含三种不同的节点。扩展节点(在 Geth 代码库中又被称为短节点)是经过优化的,负责存储一连串字符。在下图所示案例中,根节点存储了所有以a7开头的键,无需使用两个不同的节点来代表a和7。分支节点(或称 “完整节点”)包含每个可能字符的指针以及一个额外的空档来存储当前节点的值。最后,叶节点(又称值节点)的 key-end 字段必然与其所存储的 key 的后缀相匹配1。
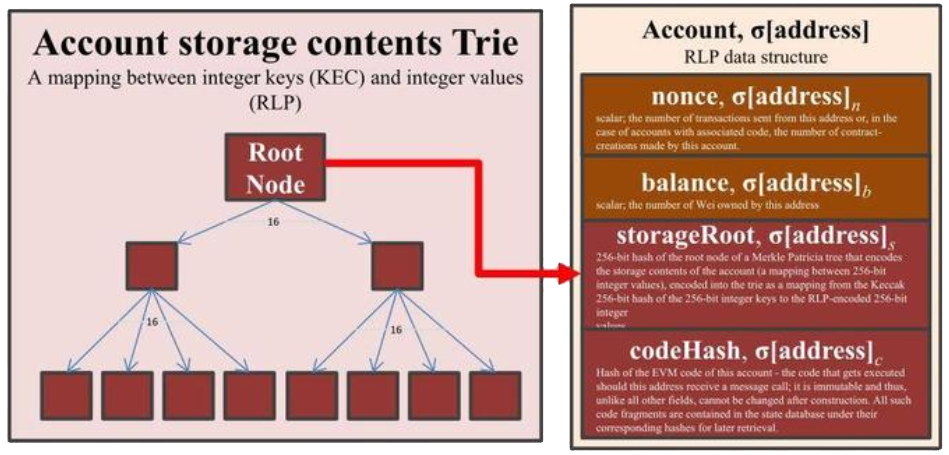
状态树 既然我们已经知道默克尔帕特里夏树是如何运作的了,我们可以开始探究什么是全局状态树。 区块链的绝大部分数据都存储在全局状态树中。虽然将状态树作为独一无二的实体包含在每个区块内这个设想看似便利,但实际上每个区块都要复制完整的状态树是极其低效的,因为每个区块之间的状态树只有细微差别。Geth 采用了不同的方案。你可以想象一下,Geth 维护了一个 MPT 节点池。每个区块的状态树只是整个池的子集。每当有新的区块被挖出或导入,就会有新的 MPT 节点被添加到池中。 要想识别节点池中的根节点,我们必须查询区块头。每个区块都包含一个指向stateRoot的字段,该字段指向 MPT 的根节点(而该 MPT存储以账户地址2作为键的账户数据)。这样一来,Geth 就可以使用我们上文描述的算法查询账户信息,如任意地址的 nonce 或余额。
请注意,如果是合约的话,账户状态将包含一个非空的storageRoot字段和codeHash字段。storageRoot字段指向另一个根节点。但是,此时所涉及的 MPT 的用途是存储该合约的存储项数据;该 MPT 会将存储空档(storage slot)作为键,将原始数据作为值。
为了将 MPT 存储在磁盘上,Geth 选择使用 LevelDB 作为数据库。然而,LevelDB 是只支持字符串到字符串映射的键值数据库,MPT 不是字符串到字符串映射。为了解决这个问题,Geth 将每个节点编写成键值对,从而实现全局状态树的扁平化:将节点的哈希值作为键,将序列化的节点作为值。这样一来,Geth 就能查询任意区块的状态树,因为区块头中的stateRoot字段就是键,可以用来查找 LevelDB 中的序列化 MPT 节点(译者注:即一棵 MPT 的根节点)。 树混乱 因此,假设你启动了一个 Geth 节点,并使用快速同步模式连接到网络。Geth 将快速下载所有区块数据,但是不执行任何事务。不久之后,你将得到一个没有状态信息的区块链。此时,Geth 通过状态下载器从 pivot 区块的stateRoot开始进行同步。 // NewSync creates a new trie data download scheduler.func NewSync(root common.Hash, database ethdb.KeyValueReader, callback LeafCallback, bloom *SyncBloom) *Sync { ts := &Sync{ database: database, membatch: newSyncMemBatch(), requests: make(map[common.Hash]*request), queue: prque.New(nil), bloom: bloom, } ts.AddSubTrie(root, 0, common.Hash{}, callback) return ts} - 来源:https://github.com/ethereum/go-ethereum/blob/87c463c47aa6d10a55a4b860bab3d53199814d01/trie/sync.go#L246-L255 - 状态下载器会向对等节点请求与 MPT 节点键对应的 MPT 节点数据。收到结果后,状态下载器会对节点数据进行哈希计算,验证得到的哈希值是否与节点键相同。如果相同,状态下载器就知道这个 MPT 节点是正确的,然后就会发送更多请求,请求该 MPT 节点的每个子节点。 // Create and schedule a request for all the children nodes requests, err := s.children(request, node) if err != nil { return committed, i, err } if len(requests) == 0 && request.deps == 0 { s.commit(request) committed = true continue } request.deps += len(requests) for _, child := range requests { s.schedule(child) } - 来源:https://github.com/ethereum/go-ethereum/blob/87c463c47aa6d10a55a4b860bab3d53199814d01/trie/sync.go#L205-L218 - 如果遇到叶节点(包含序列化的账户状态),账户的代码和状态树将排队等待被获取。 callback:=func(leaf[]byte, parentcommon.Hash) error{varobjAccountiferr:=rlp.Decode(bytes.NewReader(leaf), &obj); err!=nil{returnerr}syncer.AddSubTrie(obj.Root, **, parent, nil)syncer.AddRawEntry(common.BytesToHash(obj.CodeHash), **, parent)returnnil} - 来源:https://github.com/ethereum/go-ethereum/blob/87c463c47aa6d10a55a4b860bab3d53199814d01/core/state/sync.go#L31-L39 - 请注意同步子树和原始条目之间的区别。虽然二者都下载任意的数据块,但是如果同步器预期要同步的是原始树,它会将该数据解析为树节点,并开始同步其子节点。另一方面,如果同步器预期要同步的是原始条目,它会将数据块写入数据库并终止。 // If the item was not requested, bail outrequest:=s.requests[item.Hash]ifrequest==nil{returncommitted, i, ErrNotRequested}ifrequest.data!=nil{returncommitted, i, ErrAlreadyProcessed}// If the item is a raw entry request, commit directlyifrequest.raw{request.data=item.Datas.commit(request)committed=truecontinue} - 来源:https://github.com/ethereum/go-ethereum/blob/87c463c47aa6d10a55a4b860bab3d53199814d01/trie/sync.go#L246-L255 - 另外还要注意的是,Geth 想要多次向同一个节点发送请求的情况并不少见。例如,如果两个合约存储相同的数据,那它们的stateRoot可能相同,也有可能出现两个账户拥有同样的账户状态。在这些情况下,Geth 不想让网络充斥这些请求,因此会将它们合并。 func(s*Sync) schedule(req*request) {// If we're already requesting this node, add a new reference and stopifold, ok:=s.requests[req.hash]; ok{old.parents=append(old.parents, req.parents...)return}// Schedule the request for future retrievals.queue.Push(req.hash, int**(req.depth))s.requests[req.hash] =req} - 来源:https://github.com/ethereum/go-ethereum/blob/87c463c47aa6d10a55a4b860bab3d53199814d01/trie/sync.go#L246-L255 -然而,同步器不会合并请求的raw属性。这意味着,如果已经有了一个未决的原始条目请求,但是同步器又安排了一个具有相同哈希值的子树请求,后者将被合并,最终结果还是只有一个原始条目请求。 请记住,原始条目请求不会为了同步子节点而处理节点(不像子树请求)。这意味着,如果我们能以某种方式在原始条目和子树节点之间引发冲突,我们就能让 Geth 同步一个不完整的状态树。另外,遇到一个本地不存在的树节点时,Geth 不会退出(报错),这等于是假设,如果下载器报告同步成功,这种(本地缺失状态数据的)情况就不会发生。这就意味着,缺少一个树节点的 Geth 节点在行为上与其它完全同步树的节点截然不同。 那么,如何引发冲突呢?事实证明非常简单:我们只需用我们控制的某个合约的序列化状态根部署另一个合约,因此该合约代码的哈希值必定与(我们所控制的合约的)状态根哈希值相同,这就意味着如果合约代码先同步,另一个合约的状态树不会被全部下载下来。 综上 如果有人利用这个漏洞作恶,需完成要多个步骤并等待很长时间。 首先,我们部署一个合约(我们会利用漏洞将这个合约的状态树覆盖掉)。这个合约应该有一个独一无二的stateRoot,从而避免与这个stateRoot相关的 MPT 节点提前同步。 contract Discrepancy { uint public magic = 1; 接着,我们部署第二个合约,以便利用矛盾触发硬分叉。 contract Hardfork { function hardfork(Discrepancy target) public { require(target.magic() == 0, \"no discrepancy found\"); 最后,我们用Discrepancy合约的状态根作为代码部署第三个合约。这里我们必须注意一点,第三个合约的地址要比 Discrepancy 合约的地址 “小”,从而确保它始终先于 Discrepancy 合约同步。 contract Exploit { constructor(bytes memory stateRoot) public { assembly { return(add(stateRoot, 0x20), mload(stateRoot)) } }} 现在我们就大功告成了。当新的 Geth 节点使用快速同步加入网络时,它们会先请求Exploit合约,同步其状态子树及代码。当Exploit合约的代码被同步时,它会创建一个看起来与Discrepancy的状态根请求完全相同的原始条目请求,但它不会被当作子树请求处理。这意味着,该节点永远不会下载Discrepancy的状态 trie,因此未来读取magic的请求将返回0而非1。 经过足够长的时间后,我们要做的就是调用Hardfork.hardfork(discrepancy)。每个正确同步整个网络的节点都会看到一个回滚交易,而每个使用快速同步加入网络的 Geth 节点都会看到一个成功的交易。这将导致一个区块产生两个不同的状态根,也就是说我们可以随心所欲地触发链分裂。 Geth 团队通过处理 PR #21039 中的树读取错误快速解决了该攻击,然后通过区分 PR #21080中的代码部分和树部分完全修复了这个漏洞。 结论 这是一个非常有趣的漏洞,它可以让攻击者在以太坊网络上设置一个 “**”,并随时引爆,从而导致所有使用快速同步的 Geth 节点从主网中分叉。这个陷阱利用的是 Geth 的同步和数据存储代码中极其复杂的逻辑,这或许是它很长时间来都没有引起人们注意的原因。 敬请期待本系列的第三篇也是最后一篇文章。在这篇文章中,我们将探索 Geth 客户端的最新 bug,具体细节不便透露。 脚注 从技术层面来说,Geth 中的值节点不包含后缀。你可以将其理解成一个后面跟着值节点(只包含原始数据)的扩展节点。实际上,Geth 使用的是 “安全的 trie”,即,通过 SHA-3 算法对所有键进行哈希计算,从而确保所有键都是固定长度。原文链接: https://samczsun.com/booby-trapping-the-ethereum-blockchain/ 作者:samczsun 翻译&校对:闵敏 &阿剑—- 编译者/作者:EthFans 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
引介 | 在以太坊上安装 “**”
2021-06-10 EthFans 来源:区块链网络




LOADING...
相关阅读:
- 【深度思考】美国司法部追回BTC这件事情对于匿名信隐私币的思考,已2021-06-10
- XT.COM即将上线HTZ(HertzNetwork)2021-06-10
- 人在江湖,不要多管闲事2021-06-10
- 蜜獾交易所(PingEx)从这里认识2021-06-10
- 数字经济之区块链+数字工业2021-06-10