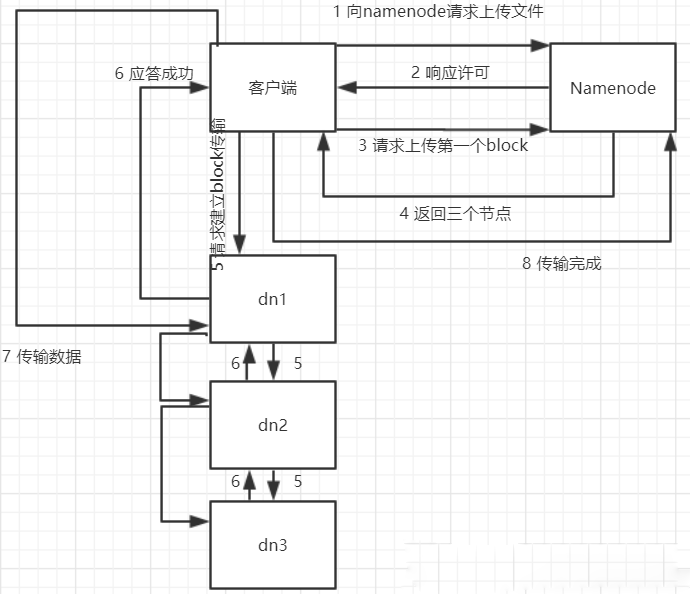
| HDFS(HadoopDistributed File System)分布式存储就是将大量的文件分散存储在不同的服务器上,通过网络技术进行连接构成一个统一的整体。 什么是分布式存储 HDFS(HadoopDistributed File System)分布式存储就是将大量的文件分散存储在不同的服务器上,通过网络技术进行连接构成一个统一的整体。 hdfs是用什么方式存储的? HDFS数据存储单元(block) 一、文件被切分成固定大小的文件块 1、默认数据大小为64MB,可配置 2、若文件大小不到64MB,则单独存储为一个block 简述: 客户端向namenode请求上传文件,namenode检查目标路径的环境是否已存在。 namenode返回上传应答。 block上传到哪几个DN节点。 namenode返回3个节点,分别为dn1、dn2、dn3。 客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。 dn1、dn2、dn3逐级应答 客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待。当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。
第三步。 简单的源码分析: 客户端通过调用DistributedFileSystem的create方法创建新文件。 DistributedFileSystem通过RPC调用namenode去创建一个新文件,创建前, namenode检查环境。如果通过, namenode就会记录下新文件,否则就会抛出IO异常。 前两步结束后,会返回FSDataOutputStream的对象,与读文件的时候相似, FSDataOutputStream被封装成DFSOutputStream。DFSOutputStream可以协调namenode和 datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小的packet,然后排成队 列data quene(数据队列)。 DataStreamer会去处理接受data quene,它先询问namenode这个新的block最适合存储的在哪几个datanode里(比如重复数是3,那么就找到3个最适合的 datanode),把他们排成一个pipeline。DataStreamer把packet按队列输出到管道的第一个datanode中,第一个 datanode又把packet输出到第二个datanode中,以此类推。 DFSOutputStream还有一个对列叫ack quene,也是由packet组成,等待datanode的收到响应,当pipeline中的所有datanode都表示已经收到的时候,这时ack quene才会把对应的packet包移除掉。 如果在写的过程中某个datanode发生错误,会采取以下几步: 1)pipeline被关闭掉; 2)为了防止防止丢包ack quene里的packet会同步到data quene里; 3)把产生错误的datanode上当前在写但未完成的block删掉; 4)block剩下的部分被写到剩下的两个正常的datanode中; 5)namenode找到另外的datanode去创建这个块的复制。当然,这些操作对客户端来说是无感知的。 客户端完成写数据后调用close方法关闭写入流。 DataStreamer把剩余得包都刷到pipeline里,然后等待ack信息,收到最后一个ack后,通知datanode把文件标视为已完成。 以上是本篇文章的全部内容,更多相关信息,敬请关注。 本文来源:HDFS.CLOUD —- 编译者/作者:HDFS.CLOUD 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
hdfs是用什么方式管理存储的?
2020-08-24 HDFS.CLOUD 来源:火星财经
LOADING...
相关阅读:
- Filecoin项目调研——投资者该如何进行选择?2020-08-24
- Filecoin大矿工测试,正式倒计时!更有425万枚FIL币奖励2020-08-24
- 太空竞赛它真的来来来啦2020-08-24
- 全方位分析Filecoin到底值不值得投资2020-08-24
- BigBang Core | 周报(2020年8月17日-8月21日)2020-08-23