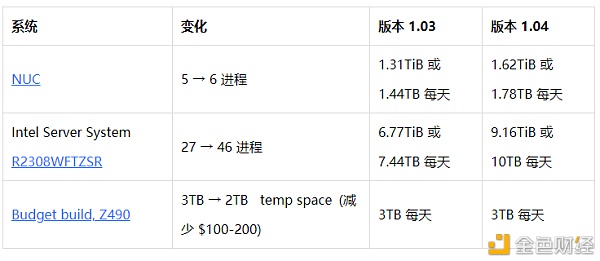
下面是通过对1.04 beta版与1.03版本测试所得的数据 实际绘图改进的示例
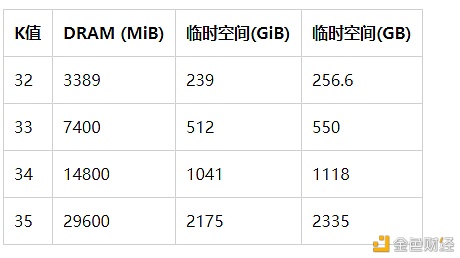
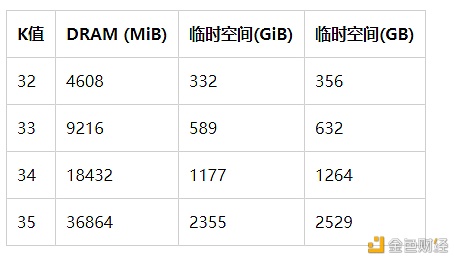
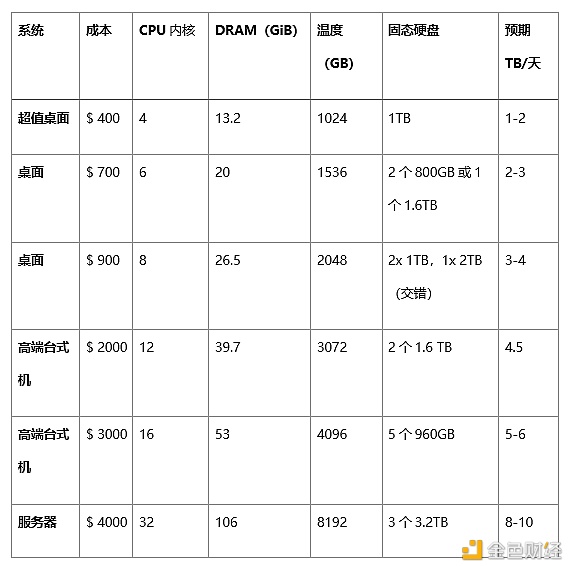
1.04版本中对临时空间和内存要求
1.03版本及以前的要求:
系统和构建选项
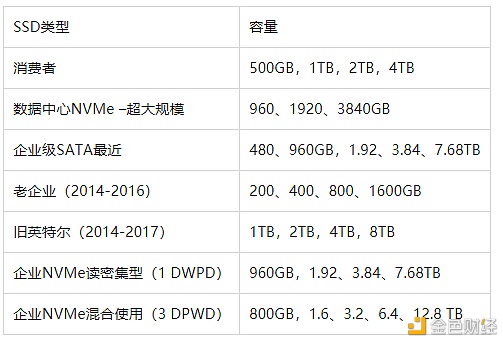
1. 关于错开调度? 在绘图过程开始之前的错开或延迟,可以帮助最大化的利用计算(CPU),内存(DRAM)和磁盘(临时空间)资源,因为绘图过程的不同阶段需要这些资源的数量不同。在八核中端台式机系统中,错开调度主要优势在于:将八个进程压缩到32GB DDR4中,而无需进程交换(减速)或被杀死(内存不足)。这加快了阶段1的完成时间。内存减少主要是由于绘图过程的阶段2和阶段3是最消耗内存的进程,确保所有进程不在此阶段同时进行,意味着更好地共享内存资源。此外,还产生了一个次要的效果,即无法同时破坏具有从第二个临时目录(-2)到最终目标目录(-d)的多个文件副本的目标磁盘。 如果用户仅使用单个驱动器,就非常的划算,因为硬盘驱动器带宽为?100-275MB / s(取决于磁盘的容量),在当n值大于1时,将会延迟后续进程的开始。 2. 超线程会有哪些变化呢? 在1.04中,与物理硬件CPU内核相比,另一个运行更多进程的领域是超线程,之所以被称为超线程,因为CPU线程数通常是物理内核的2倍。现在更可能会出现内存不平衡的情况,因为DRAM具有2、16GB,32GB,64GB等多种类型,而使用不均衡的DIMM将会减少内存带宽。在八进程八核的系统中,只有26.5GiB的内存可以用,但又会导致系统利用率不足。现在操作系统使用闲置的内存进行缓存,如果用户使用的是GUI或台式机版本,则系统所用的内存空间会更高。这里还有额外的十项流程测试,以查看特定系统是否可以以固定成本提供更高的总输出量,以及将绘图流程超额订购到物理CPU内核,用更多的内存和临时空间,能够在多大的程度上增加输出量(与构建第二个系统相比)。十个进程的容量也略高于32GB,并且需要进行大量测试以查看是否有可能。 3. 位域与无位域(Bitfield vs. no bitfield)? 在大多数情况下,位域的改进可能会使默认绘图仪更快。 较少的数据写入量和改进的排序速度将有助于更多的并行处理。 社区将在接下来的几周内发现一些令人兴奋的数据,但是就目前而言,在1.04 版本上完成的大多数测试都是使用启用了位域的(默认)绘图仪设置进行的。 4. 对SSD的耐久力影响? 1.04绘图仪中的代码的改进,将每K=32的数据写入量,从1.6TiB(位域)和1.8TiB(-e)减少到约1.4TiB(即将推出,现在开始测量!) 5. 对临时所需SSD的影响 SSD有多种形状和尺寸,用于绘制数据的最佳SSD是数据中心SSD。您必须根据所获得的硬件,去计算,在每个系统的所需不同数量的驱动器。对于RAID 0而言,容量较小的SSD通常优于较大型号的SSD,由于较小的SSD比较大的型号具有更高的单位TB的吞吐量和带宽。此外还需权衡SSD的物理配置与和价格。在计算临时存储空间时,可以将标签容量(下)与临时空间表(上)中的GB列一起使用,或从操作系统显示的内容转换为GiB。
这里没有关于SSD容量的行业标准。不同的供应商可能具有不同大小的SSD, 由于来自其他供应商的NAND裸片具有不同的物理尺寸以及SSD控制器也有不同的通道,因此。 JEDEC标准的32GB裸片不是32GB,不是32GiB,而是更大,因为存在一定数量的平面,每个平面有擦除块,每个擦除块有NAND页面,其中有许多冗余块。 尽管没有行业标准,但使用SSD的超大规模数据中心客户和OEM(原始设备制造商)所需整合的容量,都在上表中了。 关于1.04版本的总结 1.04是一个鼓舞人心的版本,特别是对于那些已经在Chia alpha中看到绘图仪的人。该团队已经走了很长一段路,以使绘图过程所需的资源更少,并且各种形状和大小的硬件都可以更容易地访问它们。我相信未来几周将出现一个新的价值绘图系统,作为TB /天/美元的明显赢家。同时,请关注Chia Network Token,以获得最新的绘图基准! Rostislav是Chia的开发人员,通过与他的对话,我们可以得出这样的结论:1.04版本的Chia是空间代码正发生变化的证据
减少在阶段3的第二遍中编写的条目的大小 https://github.com/Chia-Network/chiapos/commit/50856aacfd7fc19b3b9115e237ff2cec2a2904b9 减少在第1阶段和第2阶段编写的条目的大小 https://github.com/Chia-Network/chiapos/commit/f346f2e23537f8394da2e71f8416af6c63723a5b
在阶段2和3中将sort_key的大小从k + 1减少到k位 https://github.com/Chia-Network/chiapos/commit/7bacb3ad0beae320bcfd3ca5b54f51b46e4b82da 在阶段3中,将new_pos的大小从k +1减少到k位 https://github.com/Chia-Network/chiapos/commit/16b61a5b5d5eef76fe298fd55eecfe7733b91302 最后,在1.0.3版本中已经包含了另一个更改,但它与最近的更改特别相关,在某些情况下,我们只使用了一半的可用内存缓冲区,而不是全部使用 在阶段3和阶段4中使用所有分配的内存进行排序 https://github.com/Chia-Network/chiapos/commit/ee238ab9de52fd22a25b2360b23c331bc4187e62 —- 编译者/作者:TokenWorld 玩币族申明:玩币族作为开放的资讯翻译/分享平台,所提供的所有资讯仅代表作者个人观点,与玩币族平台立场无关,且不构成任何投资理财建议。文章版权归原作者所有。 |
一文解读如何通过Chia1.04版本提升挖矿收益
2021-04-21 TokenWorld 来源:区块链网络
LOADING...
相关阅读:
- 不再只停留在规划阶段区块链3.0的Filecoin生态和现实发展2021-04-20
- 去中心化稳定币协议 Lien 发布 V2 版本,用户可交易尚未到期的期权合约2021-04-20
- 去中心化跨链借贷平台 Wing 上线新产品池「Any Pool」 Beta 版本2021-04-20
- 福克斯商业新闻:拜登团队正在研究加密市场监管方案,尚处于早期阶2021-04-20
- 双周报丨IOST主网OlympusV3.6.0版本已正式上线2021-04-19